Welcome
Today isn’t a weekly update, since I did one a few days ago, instead I wanted to discuss something specifically to do with moving between Assembly and C. So, in a smaller, shorter capacity, this is a follow up to the previous post about translating assembly code.
I was recently implementing a function for the utilities file called ‘inside’. This function is generally pretty simple, just checking if a given point is within a given distance of another point. There are many ways one could implement such a function, but the one chosen by The Immortal makes use of a fairly complicated bit of branching if you aren’t used to it. It branches almost entirely on the carry flag, and because it is all within a fairly small space, it can branch in and out of nested statements with ease. The complication is what it brings up for the concept of control flow, and how Assembly differs from modern programming languages. The basic idea here is that any program has a logical flow of information that is dictated by ‘control’ statements. These statements, labels, and structures are like rocks in a river. The water is always flowing, and the rocks in the path change the direction of that flow, or even prevent it from moving further. Of course there are also jump statements, which are more like the water falling into a container and the container being carried somewhere else. Let’s leave the analogy there before it gets harder to track… Jump statements in Assembly are exactly what they sound like, they jump to another position in memory. In higher level languages however the equivalent would likely be stack frames. Or rather, jump statements are reinterpreted in higher level languages to be larger order control structures, rather than simple address A to address B movement. However what I want to focus on are branch statements, because these are more complicated to translate directly. The structure of a subroutine in Assembly is pretty straightforward to translate into a function in C, because they accomplish more or less the same thing and are used in similar ways. However translating a system of branches can become much more complicated than it may seem at first glance. Part of this is because it is not always clear what the direct translation would be, but also because the compiler will often change the structure to something that is more efficient in Assembly after you’ve written it regardless. The function I mentioned earlier is what got me thinking about branches and interpretations recently, and I think there is something very interesting to talk about here. So without further ado, let’s start by taking a look at that function in Assembly:
(I have converted the labels to generic ‘+’ labels, and changed certain names to remove anything non-generic from the source. Also of note, ‘add’ is a macro for clc : adc)
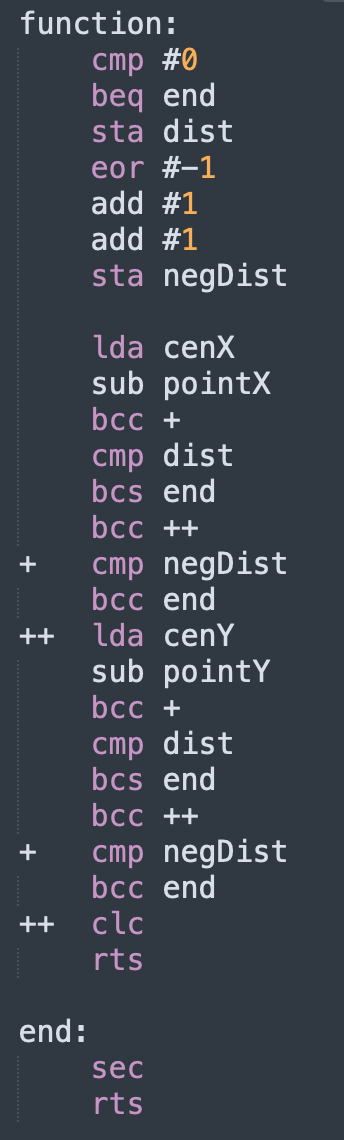
Okay, so here we can see many different branch statements. BEQ, BCS, and BCC are what dictate the flow of information in this routine, and they branch on the equal flag (Branch if EQual) and the carry flag (Branch on Carry Set, and Branch on Carry Clear). The specifics of how they branch is not super important right now though, because what we are going to do first is start to abstract the structure out so that it can be translated. The specific branch statements can not be directly translated (or at least should not be, as you do technically have a goto statement in C), so the first step is to interpret the structure in the abstract, so that it can be converted to one of the supported structures of a higher level language. It’s a little bit like a math equation that is in the wrong form to be used right now. Most of the time this step is done in your head as you read it, but I wanted to visualize the steps because I think the process has something to say about programming generally.
To start, we can identify the control statements and then group individual statements by their relation to other statements, not necessarily in the same physical order as the code is written. For example, many different statements branch to ‘end’, so we need to put that somewhere that we can connect to the others. The result is a sort of three column wide structure.
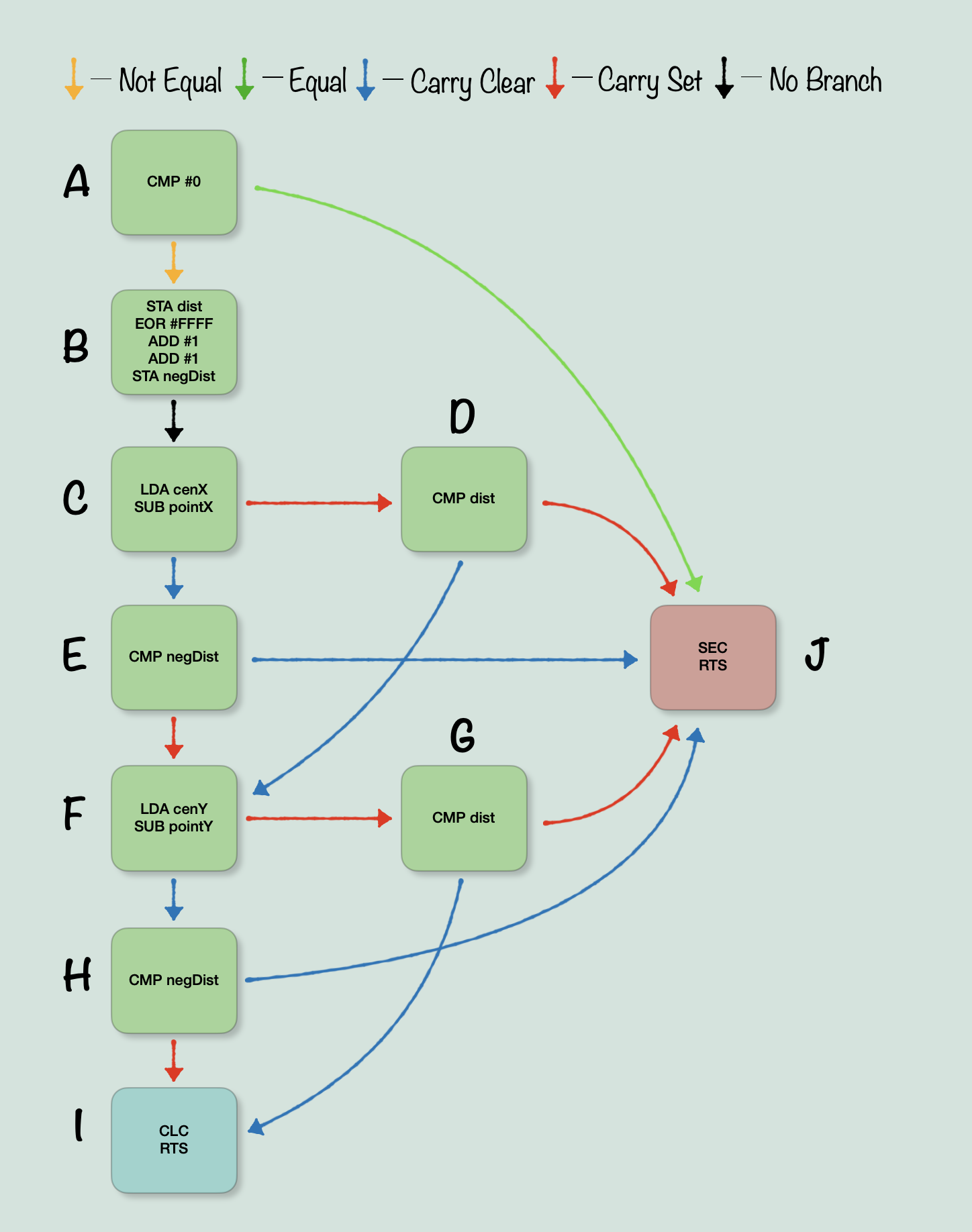
Now, what can be gleaned from this diagram? I think the most important thing to take away from it, is that many statements connect to the Carry Set exit, and only two statements connect to Carry Clear. This makes sense, as the routine needs to determine whether the point is within a given distance on any side of the point. There are two sides that are before the point, and two sides after. So having a CMP dist and CMP negDist, while all other statements have the other exit, tracks. The other important thing here, is that with the statements grouped, we no longer need the specifics of their Assembly code. We can now abstract them out to their identifiers, to make it easier to find the right control structure. The control structure in C will be abstract, so we need to make sure the one we are deciphering from this Assembly is on the same level of abstraction. So from here, we can simplify the diagram by allowing there to be multiple copies of that exit statement that so many statements connect to. The logic is the same, if A can go to J, and D can go to J, but J can not go anywhere, then the statement A -> J <- D is the same as A -> J & D -> J. This will make it much easier to find a control structure, and is something that I will come back to in the end. To be clear though, you don’t have to have multiple copies of J. In fact originally I was stubbornly writing code that preserved this aspect (I even had a great pun lined up for the post, about ‘!(E) code’, where E was a particularly convoluted statement). However as we will see, the abstract version with multiple J statements will translate much more quickly. Here’s what we get when we simplify the previous diagram:
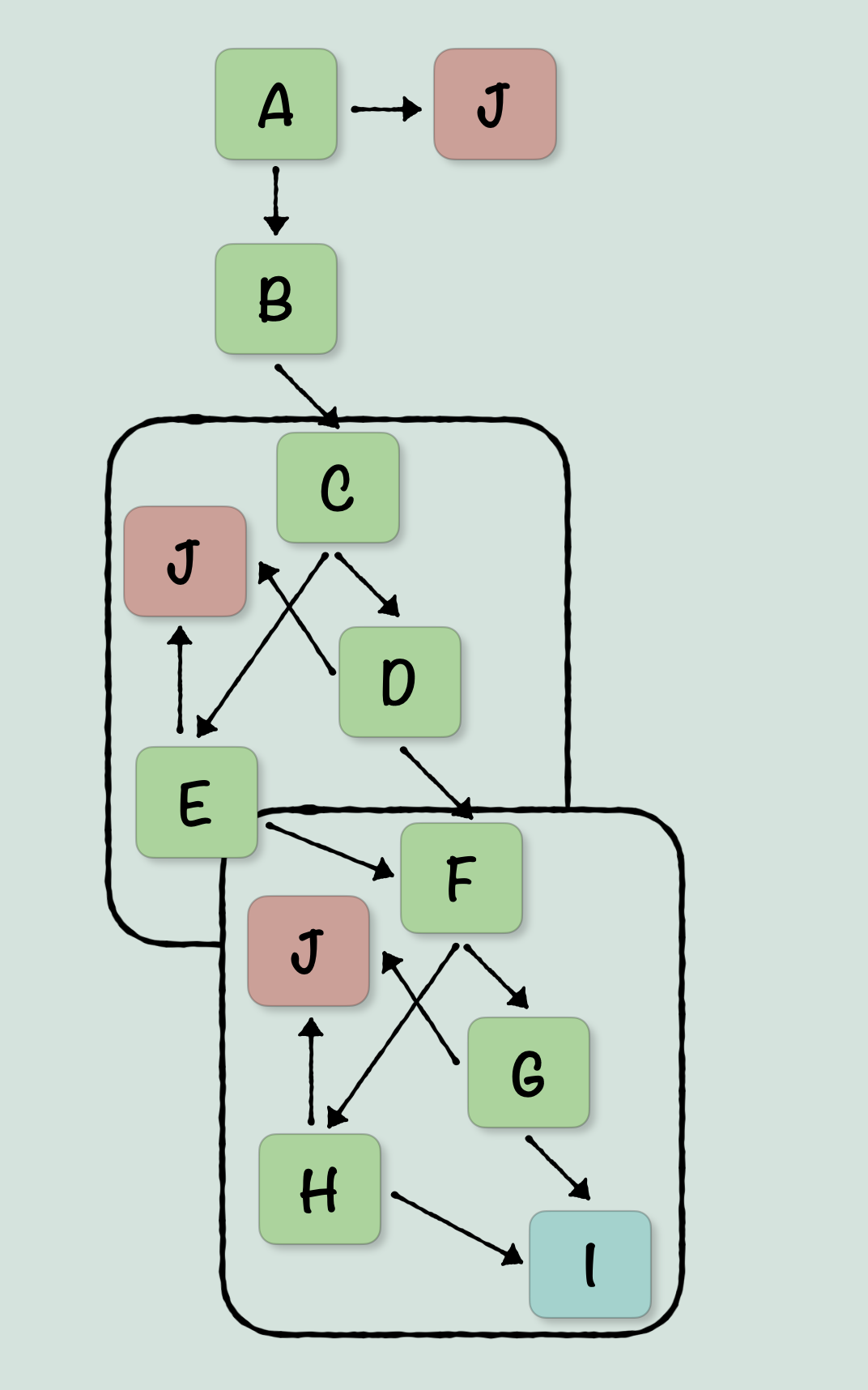
I did one other thing with this diagram, which was to highlight the two groups of statements. This is because now that the diagram is easier to read, we can see that there are simply two distinct groups of branching structures, each containing the same layout. 1 -> 2 & 3, 2 -> Carry Clear/Carry Set & 3 -> Carry Clear/Carry Set. This is crucial, because now we can start to look at this in terms of abstract control structures in C. We don’t have to care whether those statements use BCS or BEQ, those are semantics that can be replicated in C once we know the structure. What we can now latch on to, is that structure. So let’s redraw the diagram again, but this time with the C structures in mind:
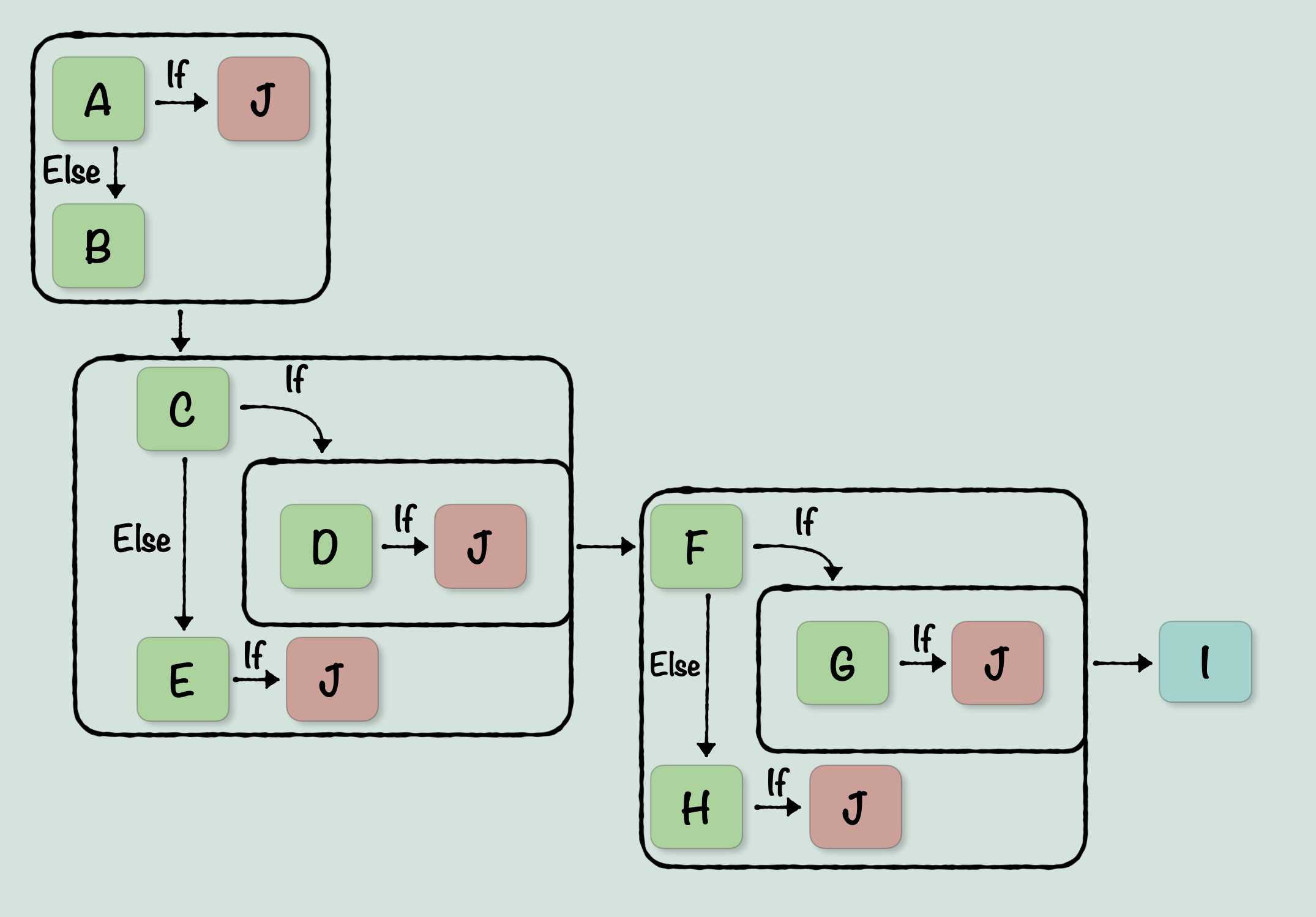
And now, we finally have something that can be directly translated into C. We have control structures based on if-else statements, and there are no convoluted, criss crossing arrows. We can take that diagram, and use it to convert the original Assembly into C like this:
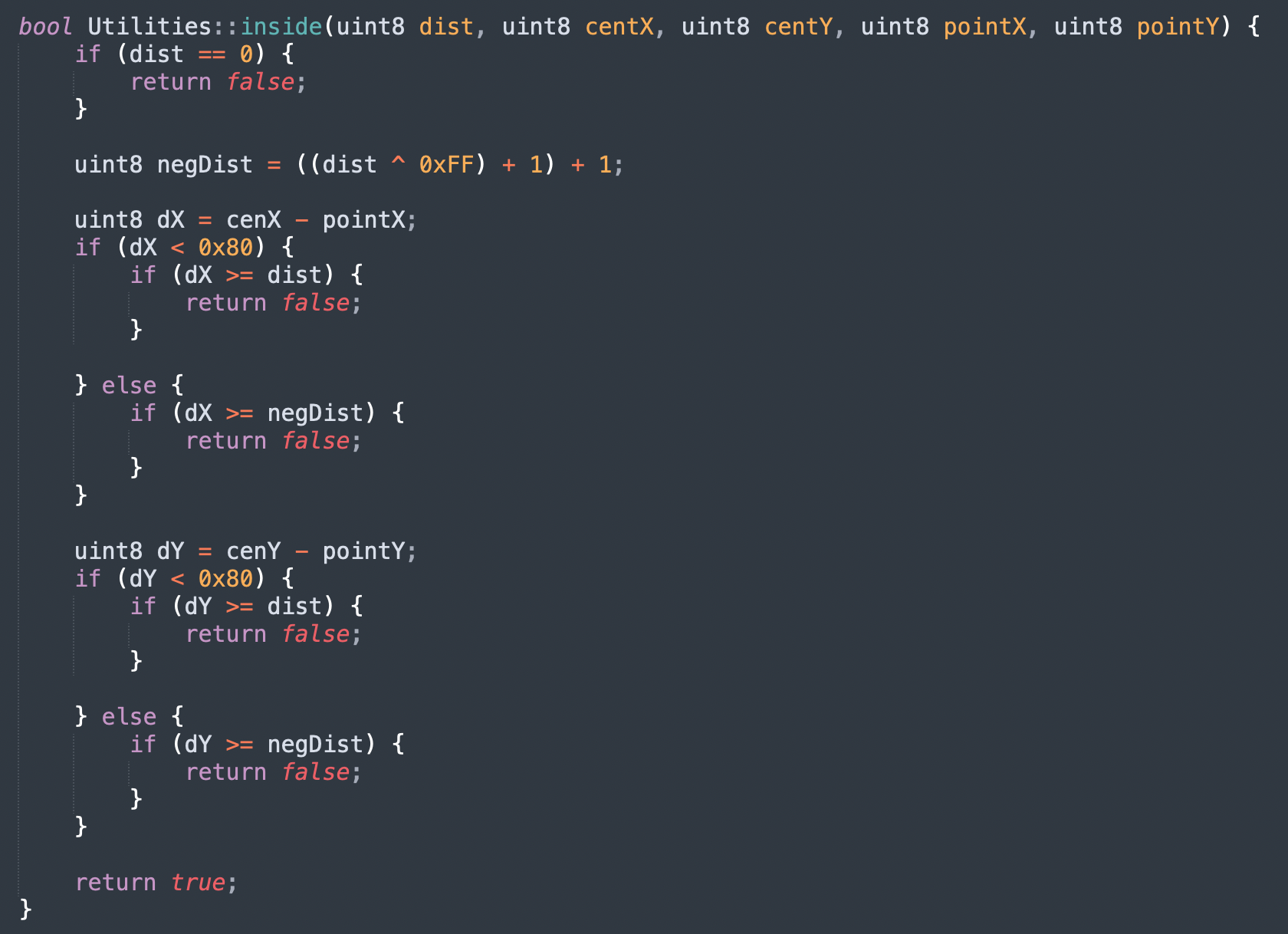
Now lastly, I want to come back to the point about having multiple J statements. As we can see from the C code, we have 4 instances of ‘return false’. This looks at first like it is not the direct translation of the Assembly, because it has multiple instances of the statement, not just references to the statement. However, what we need to keep in mind, is the level of abstraction. C code is not machine code. It can be a bit weird to think about, but where Assembly is interpreted more or less exactly as is by the assembler (the program that converts Assembly code into a string of binary), C code is not always interpreted exactly by the compiler (the program which creates Assembly code from C code). This is almost always a good thing, because the compiler is very smart and can usually find the most efficient way to write C code as Assembly. As a result, what needs to be translated is not the exact statements, it is the logic of those statements. The river can look a little different, as long as the water flows through the same path every time. On a macro level, this is actually what ScummVM does. It replaces exact machine code with logically equivalent C++ code. The result is that the game is preserved accurately (as accurately as possible without emulation of some kind), even though the code is not necessarily identical. This has a huge advantage, because just like we saw on a micro scale, preserving logic across levels of abstraction creates choice in the way it is brought back down to lower abstraction, without sacrificing the logic itself. On the scale of the code we looked at, this meant we had choice in the control structure we chose in C (for example, we could have used a switch statement instead of if-else). On a macro scale, this means the game itself can be converted to run on any modern system, despite the raw source code being anything but compatible with modern systems. I think it’s fascinating personally.
Okay, thanks for reading everyone. I’ll have a regular weekly update next week that will focus on the progress towards screen rendering. This was just something I had been thinking about while translating various functions.