Welcome Back!
Since the last post, I finished translating the decompression routines, experimented a little with displaying an image, and looked further into the structure and program flow of the game. However before diving further into that I thought it would be a good time to make this post about the process of translating Assembly into C++ (for now it’s mostly C so as to translate more directly, but can eventually be refactored into object oriented C++).
Also, small note from last week:
I need to be more careful with += statements. I was finding incorrect data being read, and after some debugging I found the problem to be this statement:
dataOffset += (_disk->readByte() << 8) * ProDOSDisk::kBlockSize;
Which, as it is written, will add the result of _disk->readByte()<<8 multiplied by the block size to dataOffset. In reality, what I meant for the logic was to have the entire statement wrapped in the multiplication, and therefor the statement needed to be:
dataOffset = (dataOffset + (_disk->readByte() << 8)) * ProDOSDisk::kBlockSize;
And for anyone curious whether the ProDOS reading code from last week is working, here’s the main window bitmap being loaded directly from the .dsk (don’t mind the fact that it’s purple instead of grey. The palette is a whole other thing. At least it’s a nice purple!):

Preface
There are a couple of things I want to go over before getting into the code, so that it’s a little easier to follow for anyone not already familiar with different programming paradigms/abstraction levels and specifically Assembly language. **Please feel free to skip this preface if that does not describe you!**
*Keep in mind this is a very surface level explanation, so there are lots of things I am leaving out to keep it focused:*
You may have heard that many games from the 70s-90s were written primarily (if not entirely) in the programming language Assembly, with The Immortal being no exception to that. But what does that mean and why is it important here? Fundamentally, programming languages can be seen as different methods of expressing a concept to a machine (so long as they are all Turing complete that is). Much the same way human languages like English and French can be used to convey largely the same thoughts to another person, programs written in different languages end up as a sequence of 1s and 0s calling hardware functions regardless of what they look like on the surface. No matter what language a program is written in by a human, the machine will only understand that sequence of 1s and 0s. As a result, unless the human wants to write their program 8 bits at a time (so-called Machine Code, where each byte (or more) represents a hardware operation (or parameter) or data), they need a way to translate some kind of natural language to that sequence of bits. This is where Assembly language comes in. Generally speaking, for any given computer architecture, it is the lowest level interface with the machine code that is written in some kind of natural language (as opposed to being strictly numerical). This language, which itself must still be compiled into machine code, allows the programmer to create complex programs manipulating the hardware of the machine. However, because assembly language is only a little bit above that machine code conceptually, it comes with advantages and disadvantages for the programmer. It is close enough to the hardware that it can perform operations directly, and explicitly, on the computer’s memory, from the smallest segments (generally the registers) to the largest pools of memory available. This direct interface allows the program to efficiently access and manipulate any part of the machine it needs to perform a given function. The flip side, is that to do so you must write everything in terms of these low level system operations. For very simple operations, this can look very short and clean. However, as the complexity of the concept being conveyed to the machine increases, the length and complexity of the assembly code increases often exponentially.
For example, take a relatively simple concept: Multiplication.
In natural language, the complexity of writing this mathematical statement is the same for any two numbers no matter the size. A * B = C. But when we bring this concept to a machine, we have to express it in practical operations it can understand, usually in terms of manipulating individual bits (for reasons I won’t go into here). And this is where details like the size of the number affect the way the statement can be expressed. For example, take the statement 5 * 2. In Assembly, you can write this operation as “Load 5, shift the bits to the left once”. The machine will take 0101 (5 in binary), and ‘shift’ the bits of the number itself over by 1 position, resulting in 1010 (10 in binary). This is because shifting the bits by 1 position is (*in general terms*) equivalent to multiplying by 2 (think decimal places multiplying by 10 in decimal numbers). But if instead we take the statement 5 * 7, the complexity changes completely. Now you need not only a way to multiply by 2, you need a way to perform that operation 7 times. You could write 5 + 5 + 5 + 5 + 5 + 5 + 5, or you could design a loop to perform the addition an arbitrary number of times, but either way the expression is written differently depending on the size of the number involved (alternatively, a special hardware register for some architectures (like the 65816) or even direct support like more modern assembly can be used. The point being A*2 is different from A*B). I know this is getting a bit involved, but I promise it will be relevant!
This brings us to the concept of Abstraction.
Hopefully that example gives an idea of why writing a program in assembly gets large and complex very quickly even for conceptually simple functions. Arithmetic is only the tip of the iceberg though. Managing memory, machine cycles, hardware interactions, status registers and flags, etc. effectively end up obfuscating the concept being expressed. And possibly the most important reason for abstraction, the machine code (and subsequent assembly) is not necessarily the same from one architecture to another (one machine might have a function X that is represented by the number 20, and another machine might have the same function with a different number, or might not even have the function at all!). This is why programming is done in layers of abstraction away from the machine code. This is a whole topic of its own, so I will only mention the relevant languages here. In terms of abstraction, you can think of machine code being the Low level and natural language as the High level. Between those two, we have different layers of abstraction serving different purposes.
Machine Code -> Assembly -> System level languages -> C (bit of a special case, can sort of be both) -> Application level (ex. Java)
With every layer of abstraction, comes a penalty to performance. Although even the high level languages end up being compiled into machine code, you generally give up a degree of efficiency when you need a program to translate abstract statements and structures into low level equivalents. As a result, if the machine running the program is limited in speed, memory, etc. or the program needs to get every bit of performance out of the hardware, some or all of the program may need to give up abstraction for performance. This balance was especially important to developing video games, because the developer often could not afford to leave any performance on the table if they wanted to make the most of the machine they were working with.
Going back to the human language analogy, we can use language to bring this together and ultimately illustrate what it means to go from assembly to C.
To do so, we can start by taking a simple concept, and walking it through the layers of abstraction. Let’s use movement as an example, where moving an object from one location to another can represent the movement of data in memory by the computer. Say you want to move a few rocks from point A to point B. We’ll start with the machine code level, which would be the physical act of moving each of them (roughly speaking). The concept of the rocks moving from point A to point B is understood solely by the act of moving them each time itself. But, if we move up to a low level language like assembly, we can express the concept instead by a statement that simply describes the act of moving it. Maybe we say “Walk to point A. Pick up rock 1. walk to point B. Put rock 1 down. Walk back to point A. Pick up rock 2, ….”. This expression of the concept still requires us to describe the way someone will physically move the rocks, and the individual steps involved, but it is more removed from the action. Now let’s move up another level of abstraction. At this point, we could say something like “Give Point B what is currently at Point A”. Notice that we no longer care what method is used to get the contents from one point and move it to another. Instead, we are closer to simply describing the goal, with an assumption that whoever is going to do it will figure out the physical method based on the environment they are in. Maybe they need a certain tool in one environment, and a different tool in another one. This level of abstraction doesn’t care about those details, and as a result can apply the same statement to similar situations in other places. At this level we are more or less talking about both the system and application levels, but if we wanted to take it even further we could move from imperative to declarative and simply say “Point B has the contents of Point A.”, but then we’re getting into other paradigms that aren’t important here (ex. functional languages). To tie this together, the same concept can be expressed in assembly and C, but in assembly the code might need to describe more steps with more details to do it. In assembly, you need to load a given value into a register (the load command and register being the details) and explicitly state where it’s going in memory.
That certainly means you have to read through more assembly code to determine the translated C version, but there is another wrinkle, and this is where it gets interesting. Looking again at that assembly statement describing the process of moving rocks, let’s now imagine that the statement was also written in Latin and that you have no idea how to read it. We’ll use a very simple version of the sentence for this:
English: “move a rock from here to there”
Latin: “hinc illuc saxum movere”
Okay, looking at the sentence we can see that the individual letters look like English, and they seem to be organized in words similar to English. So then, it should be easy enough to simply replace each word with the english literal equivalent. Let’s do that (this is not exact, and does not take into account all kinds of complexity in language, it’s just to tie programming to something familiar):
“here towards rock move”
Hmm, that still doesn’t look right. Now we have english words, but the way they are arranged doesn’t make sense. However we can at least get the general idea, that there is a rock moving towards a place. And now we can make an educated guess at the sentence, “move rock towards here”. At this point we can maybe use context to figure out where the rock is coming from and going towards, and eventually the sentence can be translated.
Okay at this point you may be wondering if I’m the cat in this gif because the relevancy of this seems like a big stretch.

But stick with me for a second and I think it’ll make sense. The reason I chose Latin for this example is that it is a language which uses a different word order from English, with the same letters. I think this highlights a fundamental difference between low and high level programming languages. If you don’t know how to read assembly, but you know how to read say, C#, you may end up going through a similar process. The words are still written in english, they aren’t alien, but right away they don’t read as natural language. Instead of words like Print, you see words like LDA and EOR. You can look up those opcodes (represents the ‘code’ for an ‘op'[eration]), and understand the individual words as Load_into_A and Exclusive_Or. But you are now presented with a different problem. The structure of the operations themselves doesn’t match what you’re used to. Once that is sorted out, there is the final issue, abstraction. You can understand the words, and the structure of the operations, but because they are on a lower level of abstraction, you also need to understand the purpose of those instructions as they relate to the hardware compared to the conceptual statements you’re used to. You might understand that LDA means Load_into_A and that the code is written LDA this : STA here, instead of here = this. But it still doesn’t tell you what the point of the statement LDA $0392 : STA $1528 is, unless you have explicit names already assigned to those addresses (which in the case of assembly source code like this project, you do have). This is different from translating between say, C# and Java, where that first stage, finding equivalent words, is where most of the process lies (for this surface level explanation I’m ignoring lots of other differences as you would expect), because the way the code works is fundamentally at the same level of abstraction (ie. neither language tends to deal in direct memory addresses).
Finally, we come back to the original question, why is Assembly important to any of this?
The Immortal was written in pure 65816 assembly, with all the hardware interaction, status registers, memory management, optimizations, and architecture specific functions that come with it. As a result, translating the source code to the high level language that ScummVM uses (C++) means translating between layers of abstraction in addition to the syntactical differences. As we will see in this blog post, the process involves first sorting the logic and movement of memory across registers and addresses, and then finding ways to closely match those interactions in C.
If you made it through this overly verbose preface, you’re awesome, I appreciate it.

Translation
Okay, with that out of the way, we can get into the code.
The compression itself is interesting, but not entirely relevant to this post, so I will just mention that the algorithm is a modified implementation of LZW, which is itself a descendant of LZ78. The modification is related to memory concerns for the Apple IIGS.
So, for translating the decompression routines, we can start by identifying all the components involved. In the file compression.gs, we have several routines, stemming from ‘myCompress’ and ‘myUnCompress’. Some of these are shared between them, as they are applicable to both.
For our purposes (we don’t need the compression routines since we are only decompressing data), the routines we will need to translate are:
– myUnCompress
– setupdictionary
– inputcode
– member
With these routines, we can look a little deeper and identify the branching structures within the routines, as well as the general purpose of the routines:
– myUnCompress
– set up the memory that will be used (essentially the memory for the dictionary and the stack of output characters that are periodically dumped to the output memory)
– initialize the dictionary
– loop :nextcode (this loop uses a jmp to return due to length)
– get the next code
– if there is a code and it’s not empty
– loop :nextsymbol (this loop uses a bra to return)
– if it is a single char
– loop :dump (another bra loop)
– process symbol
– setupdictionary
– clear the reserved memory
– set first 256 bytes as already used
– inputCode
– get the next byte from the input file
– depending on even/odd, perform a different function on it
– return the result
– member
– create a hash
– if the first entry is empty
– start the new list
– loop :ag (returned with jmp)
– find the right entry
– branch :match
– found a match, return result
– branch :next
– continue searching for match
– branch :appendlist
– loop :findempty (returned with bne)
– if empty found, add and link with dictionary, then exit routine
– if no space, reset dictionary and exit routine
Now for the purposes of this post, I just outlined them in the most surface level way. The result when I actually did this was a kind of pseudo-C code in a similar structure but detailing everything including the status flags used for branches, return values, index register usage, arithmetic, etc. This kind of stuff is not super easy to follow for the purposes of this post. Ex.
– if ((origin[index]&0xF000)|(ptk[index]&0xFF00))
The other thing I did while making the pseudo-C outline was to sort out the variables and memory addresses. This is a bit tricky with assembly, because is it not always obvious how an address or variable is being used at a glance. In C, every bit of memory used has a ‘type’. But right away that means we’re dealing with an abstraction. In assembly, the programmer might intend for an address in memory to be utilized as an integer (for example, a timer). But there is nothing stopping that data from being utilized differently. It gets a little more nuanced from there however, when we start dealing with registers. So let’s talk about registers.
On the 65816 you have 3 primary registers, with each register being a very small bit of memory right on the cpu, about as close to the action as it can possibly be. This means it can be accessed when running code, faster than virtually anything else. There are other registers as well, but they don’t really need to be explained here (when I mention status flags, those are in another register for example). The main registers are responsible for most of the operations you can perform that involve manipulating any kind of data. They are A (consisting of AB), X, and Y. These are a great example of what is explicit, and required in assembly, vs what is implicit in C.
The A register, also known as the accumulator, is primarily used to hold 1 or 2 bytes of data, so that it can have an operation performed on it. You can LDA to LoaD into A, and you can STA to STore A to an address. But this is also where operations like ASL (Arithmetic Shift Left, the multiply by 2 operation mentioned earlier) take place. The X and Y on the other hand, are generally intended to be used as indexing registers. This is because in assembly you have to do the indexing manually. For example, we can see the difference in this statement from assembly, translated to C:
lda [ptcodew],y –> start[index]
In assembly, ‘indexing’ really just means that adding ‘,y’ or ‘,x’ to an address will ensure that the opcode it translates to will be one that takes the address, and adds the value in the Y or X register before performing its operation on it. For complete clarity, LDA is translated to many different opcodes depending on the context the compiler finds it in, but for a normal load from address statement, the compiler produces the hex value 0xAD. If the compiler instead sees LDA addr,y, it will produce the hex value 0xB9. B9 will add the contents of Y when it runs (the [ ] around the variable name on the left in this case also tells the compiler that this is indirect, so that would become 0xB1 instead, but that’s not important right now).
What this means, is that at a glance, the assembly statement on the left does not tell you what value is being used to index the address referenced by ‘ptcodew’. Where as in C, the actual indexing part is implicit, but the value used to do the indexing, is explicit. This ends up requiring the C code to have a dedicated variable just for indexing data, compared to the always available index registers in assembly. This is sort of a blessing and a curse in assembly though. Those index registers are another example of data that is generally expected to be one thing, but is not always used that way. The index registers can also act like extra 16bit registers to hold and move around data. For this reason, when reading assembly code like this you have to be sure you know where that Y value came from, and keep track of what happens to it. For an example of exactly that, lets take a look at this line:
sta [pstack],y
Right here, the Y register has a completely different value on the first line compared to the last. If you aren’t careful, you could miss the LDY, maybe mistaking it for a LDA, and continue reading with the assumption that it is indexing with the same value in both places. This is a pretty simple example, but the 65816 has opcodes that can swap the contents of different registers, which allows for some very complex movement of data in a small number of lines. A TXY (Transfer X into Y) or TYA can quickly make a translation of the statement more complicated.
One more note on variables and memory:
In assembly, one of the most basic operations you perform, is to manipulate individual bits. You can still do this in C, with bitwise operators (&, |, ^), but it’s less common as you have generally more memory to work with and the compiler will optimize for space to an extent anyway. In assembly however, when you do not have much space to work with, you may need to store data that is smaller than a byte or word, but larger than a bit. Decompression is a good example, where there are two pieces of information within a word (on the 65816 a Word is 2 bytes) for certain data. As a result, the code needs to extract the bits by masking the relevant ones. For C, I made this part of an enum specifically for masking bits (to allow the translation to be as direct as possible)
The relevant entry being kMask12Bit, which takes care of grabbing just the 12 bits that are used.
Once I had a handle on the memory being used, and an outline of the logic and flow of branches and routines, I could start turning it into C code.
I won’t go over every step, because much of it is what you would expect (add file compression.h and .cpp, make a namespace, etc.), but I will briefly talk about noteworthy parts.
The first one I will mention demonstrates one of the interesting things about reading assembly compared to C. In C, a function has a set of arguments, and a return value. This is a rigid structure, and it is done that way for good reason. Generally, if you want to manipulate multiple variables outside of a function, from within the function, you pass those variables as pointers in the arguments. In assembly, even the idea of a function is a little fluid. There is a stack, but there isn’t a stack frame. That is to say, there is a record of addresses when jumping to routines if that jump is made as a JSR/JSL, and an opcode can use those address to return to the point when the jump occurred (RTS/RTL), but there is no section of memory dedicated to the instance of a function. In fact, you can make every function call by manually using a JMP command to an explicit address, and then using a JMP back to it. It follows then, that without explicit local variables, the idea of a single return value is entirely up to the programmer. And often, the return value of a routine is found in the carry flag (that’s the status register things I mentioned). But it also doesn’t have to be. You can ‘return’ the A, X, or Y registers. You can also return a status flag by virtue of the last operation done before returning. The point is, a routine in 65816 assembly can be consistent in what it considers a return value, but even then the question becomes, how do you deal with a routine expecting multiple return values from a subroutine, in C?
Well there are different ways to accomplish this, but what I chose to do for inputCode (renamed as getInputCode()), was to have a boolean that represents the carry flag, be passed in by reference so that it could be utilized by the function, while allowing the actual return value of the function to be the most relevant thing, the input code. This is also because the result of that carry flag determines the status of the loop around it as well. Here is an example of the return value of this routine:
The thing to note here, is that we are left with 3 separate return values. In the A, there is the result of LSR. In the Y, there is the result of the ASL. And the CLC clears the carry flag, which is an expected output as well. SEC or CLC is often at the end of a routine to act as a binary response. It could be used as an error message (this routine didn’t do what you expected), or it could be used to denote a binary choice within the routine (routine ExampleChooseAorB has found A to be the choice). Once again, the assembly requires special care to keep track of this in case it is not always consistent.
The next example is small, but I think it demonstrates another difference in structure. The compression routines use a hashed dictionary, and the hash value itself is an example of a statement needing to perform many operations on a value in a row. Take this line:
(EOR in 65816 = XOR)So what we have here can be described in natural language like this:
‘for the current value, double it 3 times, xor with B, double, xor with B, xor with A, and double again’. In assembly, it is written more or less the same way it is described. The accumulator acts exactly like you would expect, it accumulates that value as operations are performed on it. But this is not how higher level languages generally work. For example with C, you can’t leave an equation with only one side completed, because that sort of accumulator register is not visible and therefor the result is unusable. This makes sense, because C can’t be bound by a single architecture with a single structure of registers. So in C, you must either make the entire equation one expression, or you must break it up and have faith that the compiler will sort out the best way to do it based on the architecture being used. Here is the balance I decided on with this statement:
This is pretty easy to follow, at least compared to that pseudo-C code equivalent I originally wrote down:
– h = (((((k<<3) xor k)<<1)xor k)xor codeW)<<1)
if ((((origin[codeIndex]&0xF000)&ptk[codeIndex])&0xFF00) == 0)
Which is not exactly easy to follow at a glance. So instead, to make it readable at all we need to break up the statement into components like this:
If we look back at the outline for that routine, we see that it consists of a loop and several branches. We will get back to the loop in a moment, but right away we have a decision to make. In C, a function is a distinct structure. Or to put it another way, you can’t make a function that is simultaneously a subsection of another function. In Member, we have the branch appendList, which is part of the loop but performs a distinct function, is written after the other code in the routine, and has its own exit from the entire routine. In other words, it is possibly more accurate to think of Member branching to a different subroutine, appendlist, as if the entire routine is sort of split in two. It doesn’t need to be a separate function (in its infinite versatility, C actually allows direct GoTo statements, but they are highly discouraged, and this translation will restructure as needed instead), but the code would be hard to follow and rather ugly if written this way in C. With the actual branching being part of the implicit mechanics underneath, C generally wants branching structures to be complete. Ie. You can write a while True loop and have a branch inside return from the entire routine, but that would bypass the structure of the loop. In other words, the overhead of a complete loop is generally preferred for the sake of future additions/changes, more control over the flow of logic, and readability. C really doesn’t restrict you to any particular methodology, so you can have a nested loop structure where some branches return from the loop and others the function, but it also gives us the opportunity to make the structure follow the purpose a little more clearly. So for this routine I decided to separate them into getMember() and appendList(), so that they each have a distinct focus. getMember() searches for a code in the dictionary, appendList() adds a new entry to the dictionary.Let’s start by identifying the exit points from this routine by making a simple map of the branching statements in the routine:
– Member
– beq :newlist
– :ag
– bne :next
– beq :appendlist
– :match
– return
– :newlist
– return
– :appendlist
– bcc :tablefull
– :findempty
– bcc :tablefull
– bne :findempty
– return
– :tablefull
– return
From this we can see that :next and :ag are clearly connected together, and :findempty needs :tablefull which is connected to :appendlist. But once we branch to :appendlist, there is no chance that we end up back in :next or :ag. So making it a function seems like a fairly natural translation of the structure.
Okay, we can now also identify the looping structures. I’m not going to go into the specifics of the different types of branches (bcc vs bne for example) and what they become in C, but we don’t need that to arrange the structure based on the loops. For example, if we look at :appendlist, we have :tablefull written after the loop, despite the loop having its own return and not also using :tablefull. This doesn’t technically need to change, but we can make it a little easier to read at a glance by not requiring the reader to skip past the loop to see the result. As it is, the (for this post, pseudo-)C code structure looks like this:
– appendList():
– if (condition for :tablefull not met):
– loop :findempty:
– …
– else:
– …
– return
But we can rearrange this a little bit as a result of that else branch not being used by the loop:
– appendList():
– if (condition for :tablefull IS met):
– …
– return
– loop :findempty:
– …
– return
And now, there’s no need to read past the loop just to find out what happens with the first condition.
This example may seem a little superfluous, but I chose it because in this format, the concept of branches in assembly being translated into easier to read conditionals can be fully digested. In reality, we aren’t talking about reading a few lines ahead, we’re actually talking about seeing a label, having to scroll around searching for the branch it references, keeping that branch and the sub branches, and their sub branches in mind as you go back to the first branch, which might then have several more branches going backwards and forwards in the code, branching to each other, etc. Doing this when reading the code to understand the flow of logic is unavoidable, but what we want, ideally, is to avoid translating that part of the assembly to C. Instead, we want the logic to be properly structured and contained within loops and conditionals, so that the logic is preserved, but the ability to read it (and change, fix, expand, etc.) is easier.
Basically, we want to turn this (ex. the pseudo-C):
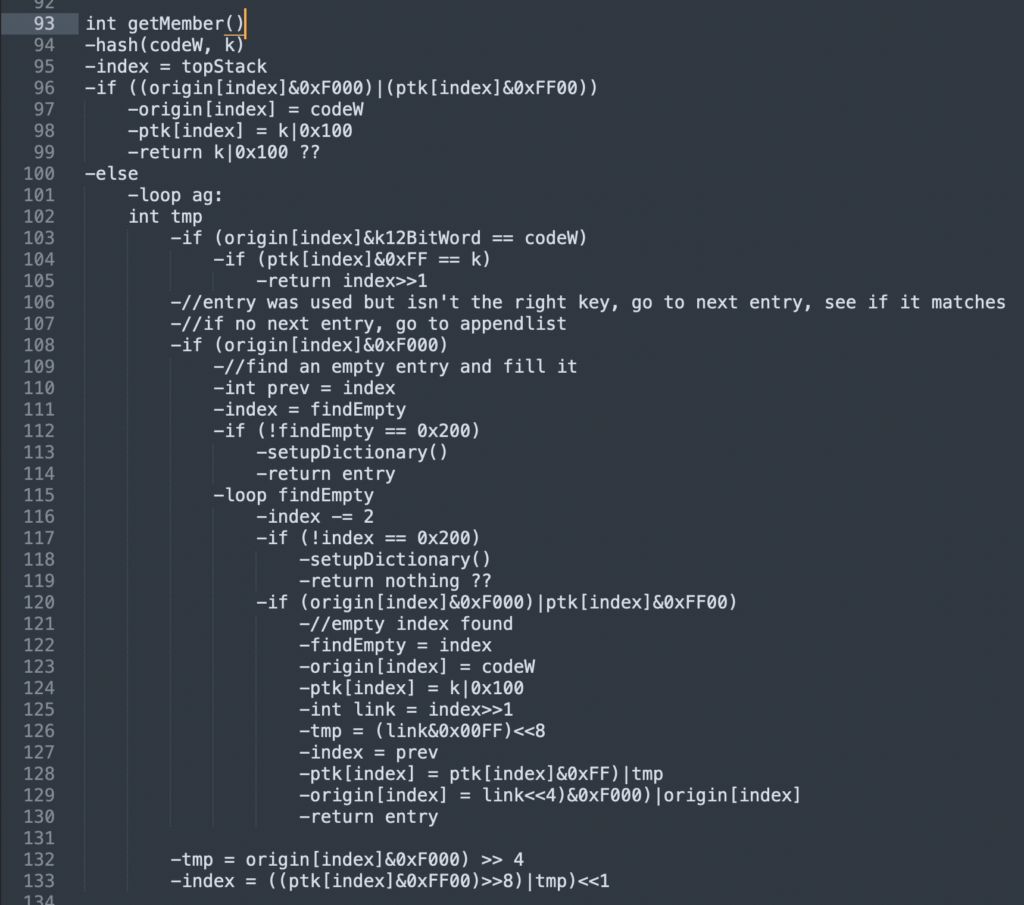
Into this (I rearranged the example conditional as I was writing it, so it’s unfortunately not visible in this):
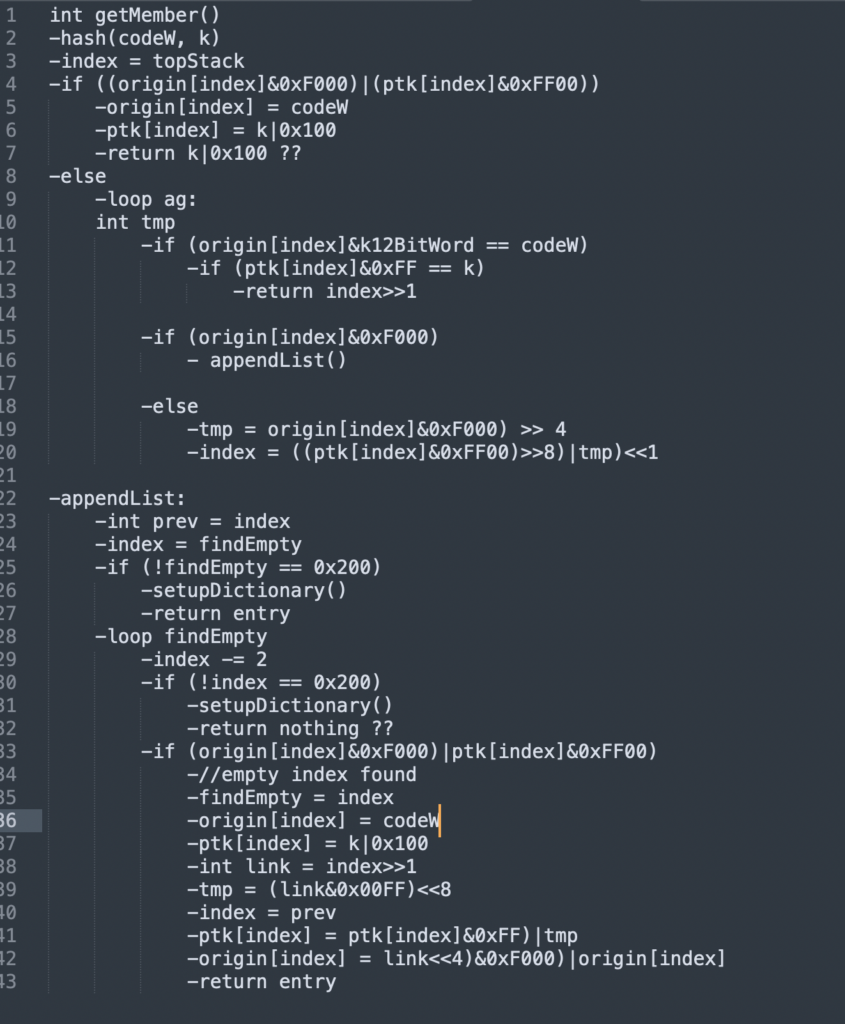
So that instead of having to digest the entire routine with the distinct subsection right in the middle of it, you can see ‘appendList()’ and have an idea of what it does, without having to dive into how it does it at the same time.
And now one final thing in getMember() that is relevant to translation. In assembly, you often have access to architecture specific operations that can do neat things due to the nature of the hardware, and these can lead to tricks and optimizations. The 65816 has a good example of this in the opcode XBA. This is a neat feature of the 65816 in particular, taking direct advantage of the way the accumulator register works. On 65816, unlike the 6502, and for reasons I won’t go into now, the 16bit accumulator is actually made up of two different 8bit registers, A and B. When operating in 16bit mode (the 65816 architecture with it’s 6502 8bit emulation mode is a whole other interesting topic), A and B act as a singular register, A. But thanks to this register actually being two distinct registers, there exists an opcode to swap the data between them, similar to the opcodes for transferring between other registers (TXY for example, Transfer X to Y). XBA (eXchange B and A) effectively reverses the byte order of a given value in the accumulator. This may not sound especially useful, but when we are looking at efficiency on the order of machine cycles, every single operation we save is useful. For example, if you have the number 0x5 in the accumulator. And you want to turn that number into 0x500, you need to multiply it by 0x100. To avoid the comparatively slow arbitrary multiplication, you can shift the bits over by one byte, requiring an ASL for every bit position, in this case 8. So that would be 8 bytes of code, one for each ASL, and each ASL takes 2 cycles, giving us a total of 16 cycles to move 0x5 to 0x500. On the other hand, since 0x5 can be read as A: 0x00, B: 0x05, we can use XBA to instantly give us 0x0500. That’s one byte for the XBA, and the XBA is 3 cycles, making it 13 cycles faster and 7 bytes shorter. That’s pretty great! But what happens when we have to translate code that makes use of this trick into C? It gets a little messy. The decompression routines have a couple of instances of this which aren’t too bad, such as:
Which I translated as:
The process for this is:
– identify the goal: XBA + AND #$00FF –> get the top byte alone, and make it the low byte for the next operation
– rearrange for C: the destination is Y (not shown in snippet), which in the C code is the variable hash. As such, we start by making hash the high byte of ptk[hash], and then we can shift down until it is the low byte through a >>= statement
But what about when XBA is used in the middle of an already complex sequence of operations on a single value? Translating the arithmetic suddenly involves a non-arithmetic component (in terms of the arithmetic around it), which can get tricky. Just another consideration during translation.
The take away from those examples is this: When translating assembly to C, there are a number of factors that are not necessarily obvious from the surface. There are two parts: Reading the assembly, and writing the C. Reading the assembly has challenges such as: keeping track of the movement of data between registers and addresses, bit manipulation, status flags (not just for branching either! Although nothing in the decompression routines does this, it can be useful to manipulate things like the carry flag within expressions themselves), and often complicated webs of branches. While writing it in C brings challenges that include: untangling and rearranging those branch webs, finding a balance in expressions between efficiency and readability, replacing non-portable register manipulation with consistent use of local variables, and fitting the dynamic movement of branches and routines into structures that are philosophically consistent with how C code in a function should flow.
Alright, we made it to the end!

If you read this whole post, first I want to say thanks! That’s pretty wild considering how long it was. And second, if you found yourself frequently thinking ‘what the heck are they talking about and what is this code supposed to do’, and/or looking up terms, then congratulations! You have a good idea of how reading assembly code feels 😛
As for what’s next in the project, I’ll talk more about it next time, but the plan currently is to start translating the files ‘kernal’ and ‘driver’, which handle much of the core structure of the game engine, using a sort of inside-out methodology that I will talk more about next time. I promise it won’t be as long as this one! Probably!