The first week of the coding period is over, and there a few things to talk about.
ProDOS File System
Last week I talked about how The Immortal is stored as .dsk files formatted as ProDOS. Since ScummVm did not have a way to read ProDOS specifically, the first thing that needed to be done was to implement some way to do so. This was a somewhat lengthy process, as I will get into shortly. First however I should mention that because ProDOS is an entire file system and not just a series of files stored together, and because accessing the files should be as similar to the original game as possible, I needed to have the engine simulate the file system. I also mentioned last time that it could eventually be converted into an implementation of the Common::Archive system in ScummVm, so that other engines reading ProDOS files would not also need to simulate the file system. There were a number of frustrating issues along the way, but I was successful in implementing a Common::Archive class that can handle ProDOS .dsk files (although it does not account for Sparse files currently, which are unlikely to be relevant for game engines but it should be noted none the less).
In the last post, I gave a brief explanation of how the file structure works. Today, I will show how it works in more detail with reference to the code.
The general structure has stayed mostly the same throughout, where the disk volume is a class, and the file itself is another. The disk volume contains structs that mirror the data layout in the disk, for example a directory header:
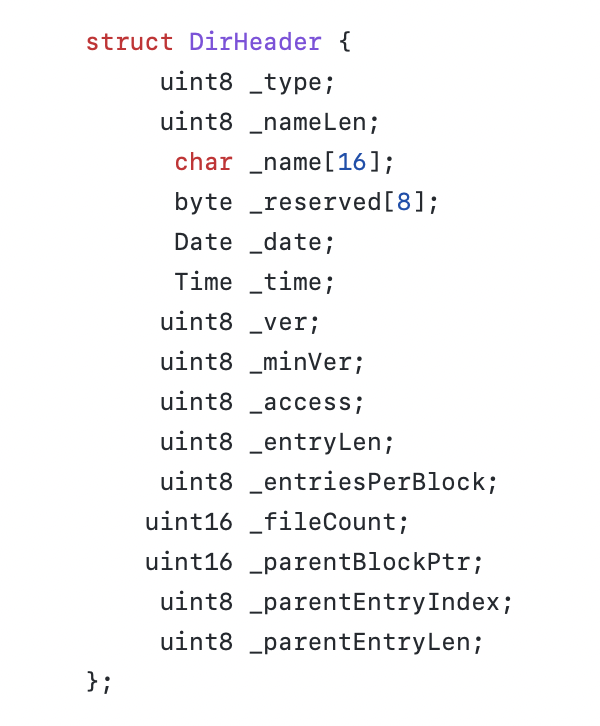
The disk class also contains methods used for parsing the entire volume, the loader blocks data, the volume bitmap, and a hashmap to hold all the file objects with their full path name as their key (ie. if a file is in a subdirectory, the path would be “subdir/file”).
The file class then, is much smaller, just containing a bit of metadata about the file (name, size, type), and a block index pointer to where either the data, or the index block/master index block is stored. It also has methods that use that block index pointer to put together the file data from its disparate data blocks when it is asked to do so.
As a result, the program flow works like this:
ProDosDisk object is created -> constructor is called -> open() method is called -> the volume is parsed by creating structs of the directory header, looping through each file entry in the directory, and if the entry is a file, creates an object for it, or if it is a subdirectory call the same method recursively until it reaches the final directory.
Then, if asked for a file, ProDosDisk gets the file object from its hashmap, and calls the method for putting the file together.
Originally, I had done this using a byte vector (Common::Array). This was because the size of the data is unknown until the file entry was parsed, so I needed a data structure that could expand. This worked well enough, and was able to return a given file when the disk object was called. However, once I started implementing Common::Archive, a number of things needed to change.
Archive
The Common::Archive class in ScummVM is designed to act as a universal container for file types. At its most basic level, it works like any other input stream. You can tell it to load a given file by its file path (the path being handled by search manager, allowing for relative file paths and removing the need to account for different OS file structure) into a Common::File object, and then use methods to seek() and read() from that data stream. However, the class can also be implemented, so that those same universal file methods can be used on file types that need to be unpacked and parsed before they can be used. Essentially, this means that an engine could use a single method for loading resources, for many different game versions that store their resources in different file types, allowing the code to stay smaller and also closer to the original game code.
What does that actually look like for the ProDOS file system?
It requires the class to implement a version of certain functions. Specifically these:
- bool hasFile(const Common::Path &path) const override;
- int listMembers(Common::ArchiveMemberList &list) const override;
- const Common::ArchiveMemberPtr getMember(const Common::Path &path) const override;
- Common::SeekableReadStream *createReadStreamForMember(const Common::Path &path) const override
Which are each called from the Common::File class. Implementing those methods brought up another issue however, which was that the file in this case was already an object. Normally, an archive class will create an object itself and call a method to get the file contents. With ProDosFile already existing however, to avoid creating an object just to call another object, I had to also implement Common::ArchiveMember. This required its own set of universal methods inside ProDosFile:
- Common::String getName() const override;
- Common::SeekableReadStream *createReadStream() const override;
- void getDataBlock(byte *memOffset, int offset, int size) const;
- int parseIndexBlock(byte *memOffset, int blockNum, int cSize) const;
Where getName and createReadStream are the archive methods, and parseIndexBlock and getDataBlock are the methods that ProDosFile uses to put together its file contents.
Then finally the file contents itself had to change as well. Archive requires a byte stream (as you would expect to get from calling Common::File), but my methods were designed to give back a byte vector. After rewriting the methods that put the file together, they now allocate a set of memory at run time, add the file contents one block at a time, stepping through the index blocks, to return a standard read stream.
A side note about those index blocks: They are a set of block index pointers to individual data blocks (or index blocks in the case of a tree file), but the way they store those indexes is very strange. I’m sure there’s a specific reason for this, but they store the low and high bytes of the pointer 256 bytes away from each other. Ie. The low bytes are stored in the first 256 bytes of the block, and then the high bytes are stored in the following 256 bytes. I’m not sure what the reasoning was, but it made it slightly more complicated to manage seeking through the file.
Result
The result of this is that the engine can now call Common::File to get a file containing only the data of a given filename, put together in the background by the ProDosDisk and ProDosFile classes, wrapped together by Archive.

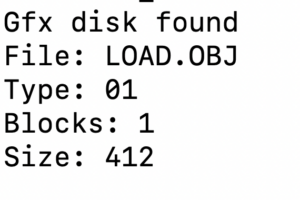
(not shown is the actual byte data, because that is just a long string of hexadecimal bytes).
Next
So I was unfortunately not able to get through the decompression function within the first week, as almost all the time was spent getting the disk file reading into the state it is now. However I have begun translating the decompression routines into C code, and I will have an update for that next week or earlier.