ScummVM Server Connection
This week was spent creating and gluing together what will be the two most used pieces of this project, the GUI for the user to verify (or submit) checksums for their files, and the API endpoint on the server so ScummVM can communicate with it.
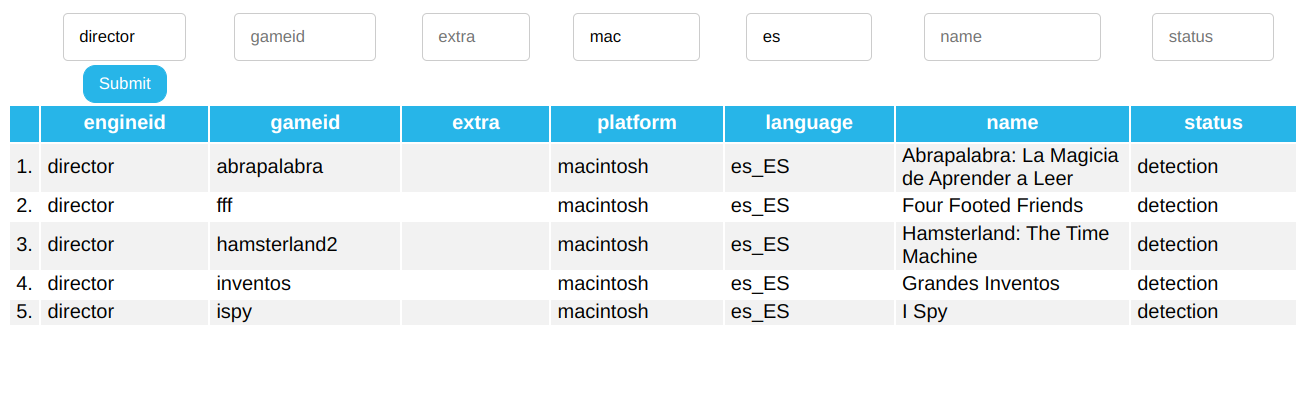
API Endpoint
An API endpoint is essentially a route (URL) that will read and respond to “requests” that you send to it.
For our application, we have a /api/validate route that accepts JSON requests, sent from ScummVM, processes the input (validates the checksums) using the functions we made last week, and sends back a JSON “response”. This is read by ScummVM, and the results of the entire process are displayed.
ScummVM GUI
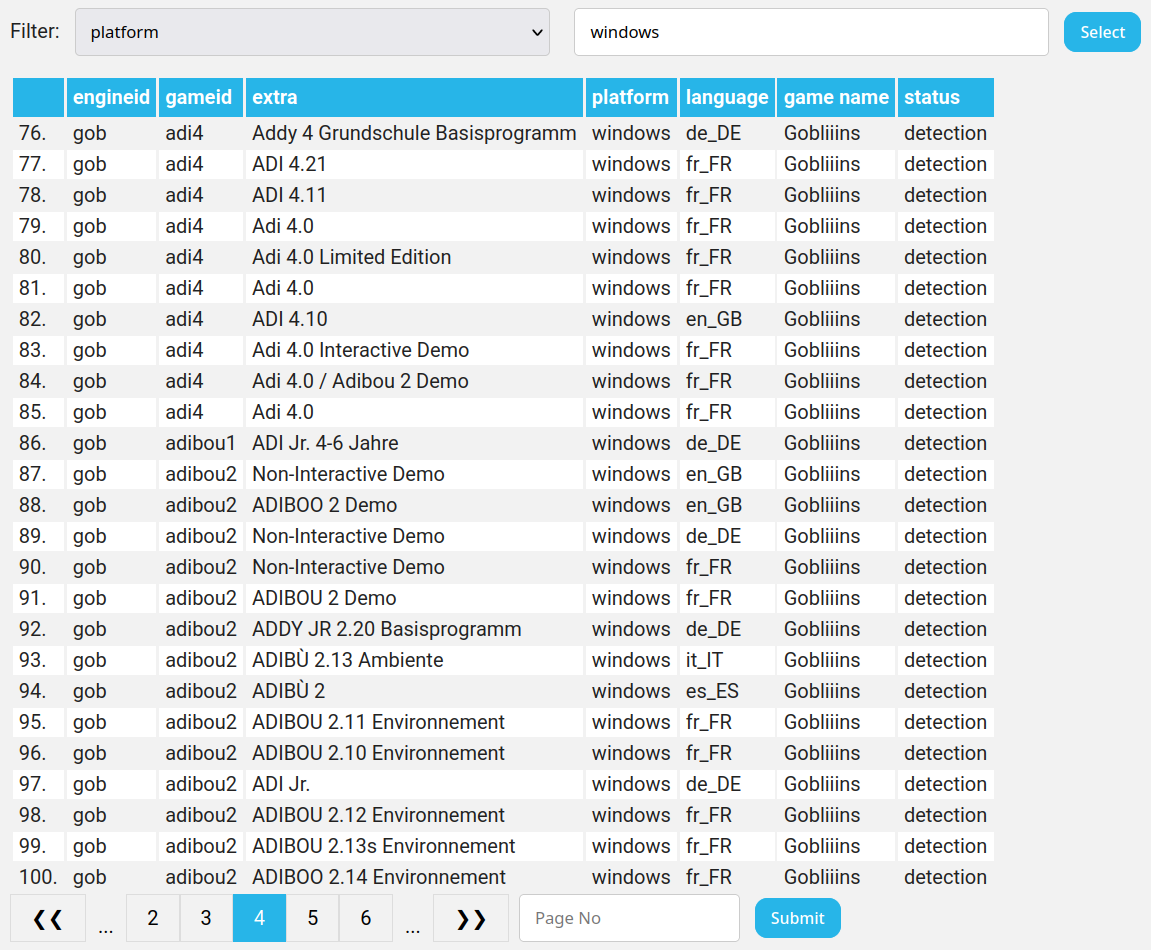
Once the project is finished, the user should be able to scan their game files and get a result of the verification. This all starts by clicking a button in the Game Options menu.
Clicking the button gives the user a small alert that this might take a while, and then the checksums are calculated. These values are then composed into the defined request format, and sent to the API endpoint as part of the body of a POST request.
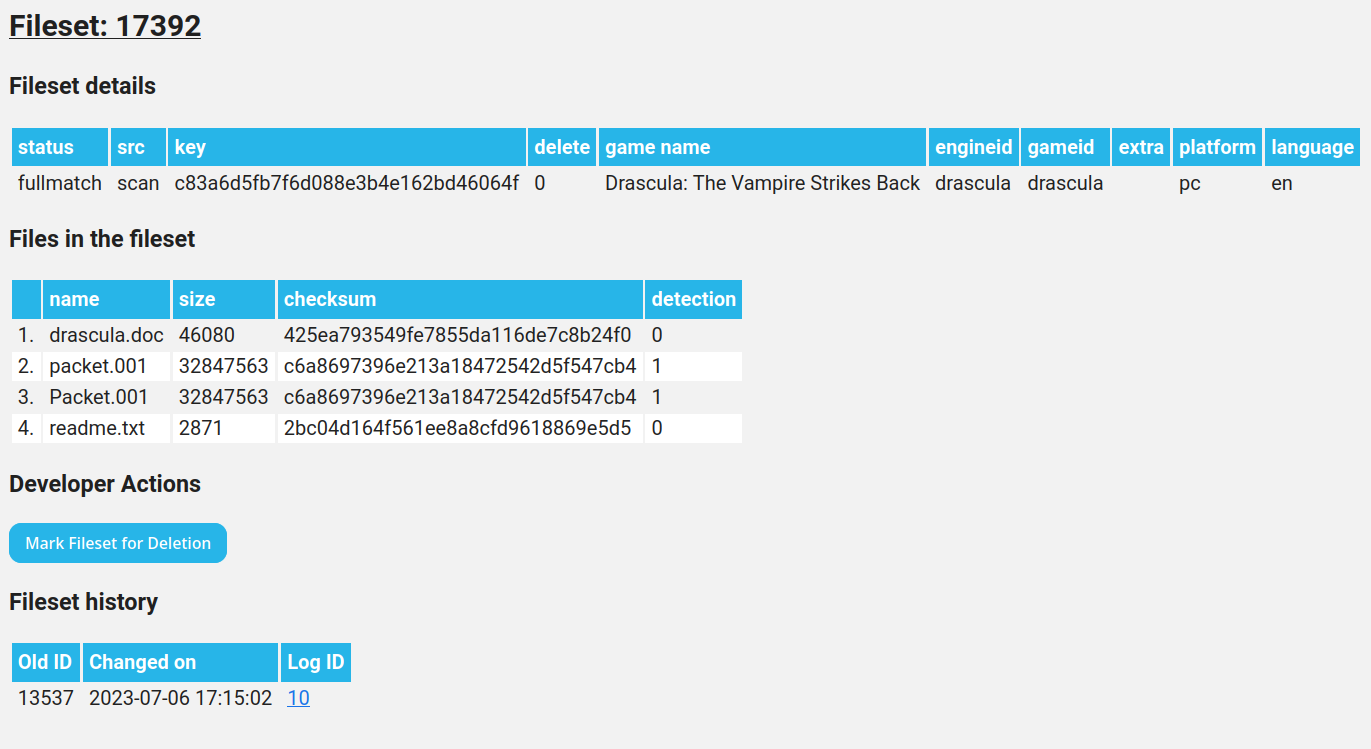
After the request is sent, it is received by the server, processed, and a response is sent back. Depending on the whether or not the game fileset is present on the server we can get varying results. If the fileset is available, we display the results of the server-side comparison on a file-by-file basis.
If the fileset is unavailable, it is inserted into the db as a user fileset and we show a dialog asking the user to send an email to us along with the ID of the new fileset so we can review it.
With all this set up, the user-facing part of the project is finally complete!
That’s all for now, hope you check in next week for more progress!
Thanks for reading!