My expectations for the week
It’s the second week of the GSoC summer! After creating the database as defined by the schema, it was time to populate it with some real values!
This week was dedicated to writing the parser for DAT files, inserting them into the db, and a CLI tool to create DATs from directories containing game files.
Part 1: Parsing DAT files
The first order of business was to actually come up with a good way to parse the DAT files. The hardest thing to do was to get the text inside the outermost brackets.
While I could simply try something like \((.|\s)+\) to match opening and closing brackets, but that would end up matching the very first ‘(‘ and the very last ‘)’ – something we don’t want if the file has multiple top-level brackets. So I had to get a little creative.
I had done some research in Week 1, and decided that recursive regex was the best option to keep the code small and maintainable (it’s not really a regular grammar anymore, but that’s besides the point). PHP uses a regex parser that is based on PCRE (Perl Compatible Regular Expressions), so recursion is built-in.
Now, to figure out how that works…
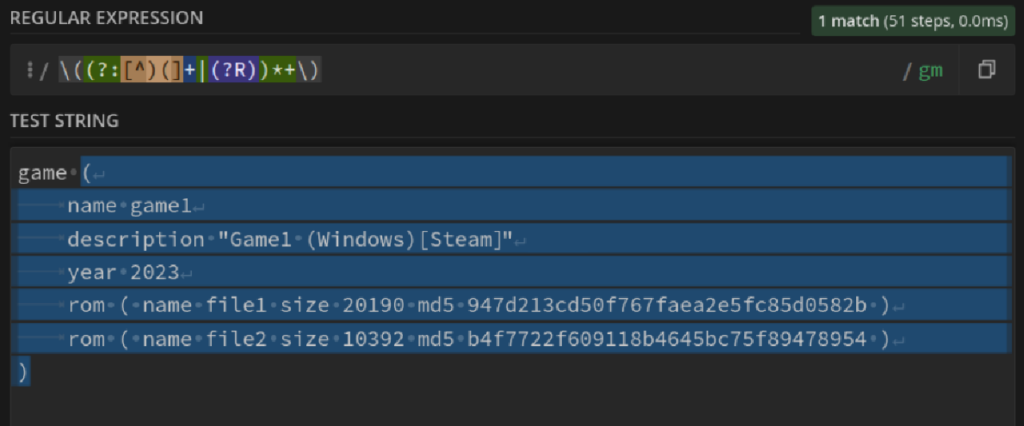
\((?:[^)(]+|(?R))*+\)This is what I came up with. The start and end are quite similar to my first guess, but let’s take a look at the inner part of the expression.
The (?:[^)(]+|(?R))*+ is a non-capturing group, and it matches either [^)(]+ or (?R) zero or more times. [^)(]+ simply matches anything that isn’t a bracket, but (?R) is the real special sauce. It will cause the pattern to recursively match itself, which means any nested brackets are matched in this group.
This leaves only the top-level closing bracket to match the outermost (the first) opening bracket, giving us exactly what we want!
Once we have this data, we can extract the checksum data inside the brackets using a much simpler parsing technique, splitting by spaces. Checksum data is in the format rom ( values ). We then split the values by spaces to get the name, size, and checksum value. Quite straightforward compared to what we just did! We can store this data as key-value pairs, which are called associated arrays in PHP.
Part 2: Inserting the data into the DB
I’ll keep this part short – I simply needed to loop through the data, extract the metadata we need (only the engine name for now) and insert into the right tables.
Everything was easy to do, but when I was testing it out with large DAT files, I took forever to actually run. Why? Because insert queries, when executed one by one, are very slow. The largest of the DAT files have ~100k files with 3 checksums each, and each file needs 4 insertions. That’s well over a million queries.
The fix for this was easy enough, just wrap it in a transaction ?. This reduced the running time to a much more manageable 2 minutes. Good enough for now!
Part 3: CLI application
The CLI application is still a work in progress at the moment, but I wanted to mention it here since I got the most important functionality out of the way – calculating the checksums of all the files in a given directory.
This gives the devs that have game files an easy way to create DAT files similar to the ones we were parsing earlier, so that they can then add the checksum data into the database.
There’s still stuff left to do – along with actually creating the interface part of the application, I also have to write the data into a DAT file. Shouldn’t be too hard, since it in basically the inverse of the parsing functionality we made earlier.
That’s all for now, hope you check in next week for more progress!
Thanks for reading!