Revisiting the DATs
This week was spent adding additional features to the main framework of the project – the parser and the scan utility. I also changed up the UI of the website.
MacBinaries
In Classic MacOS, one file could have both a resource fork and a data fork. These were physically separate files, but were treated as one object by the OS. While MacOS handled this fine, transmission protocols couldn’t do the same.
Enter MacBinary – a file format that combines both the forks into one file, suitable for transmission over the interwebs, and also, capable of being used on other file systems. ScummVM relies on MacBinaries to handle files from classic MacOS games, which means my scanner should handle them too.
MacBinary files need to be treated differently because the detection happens based on the checksums of the forks, not the whole file – which means I needed to create functionality to detect MacBinaries, and then calculate checksums of their forks for matching.
The difficulty of this part came from identification of the MacBinaries. I had to translate C++ code into some complicated looking Python, and implement a custom CRC function. Took a couple tries, but it works now!
Incremental DATs
The parser is built to read and interpret DATs, and then insert them into the db as is. This feature would add an additional check to prevent the duplicate entries from being inserted when a DAT with the same entries is uploaded.
Implementing this feature efficiently took some thinking (and refactoring!), but I managed to get it to work!
I first had to add an extra column – timestamp – to the fileset table to determine whether a detection entry was outdated (meaning it wasn’t present in the latest detection entries DAT). These entries were marked as obsolete. During insertion, I checked if the detection fileset was already present in the table, with the help of the value in the key column (a unique identifier of sorts). These entries were skipped during insertion.
For DATs coming from the scanner or clrmamepro, it’s a little more tricky. If a game is detected, we can compare the filesets associated with that game, and mark the new fileset for removal if they are the same. We decided to leave removal of unmatched duplicate filesets for a later date, as handling this scenario needs a little more set up.
Some smaller changes
I had also updated the scanner to handle filenames with punycode, and added support for custom checksum sizes (the printing didn’t work before).
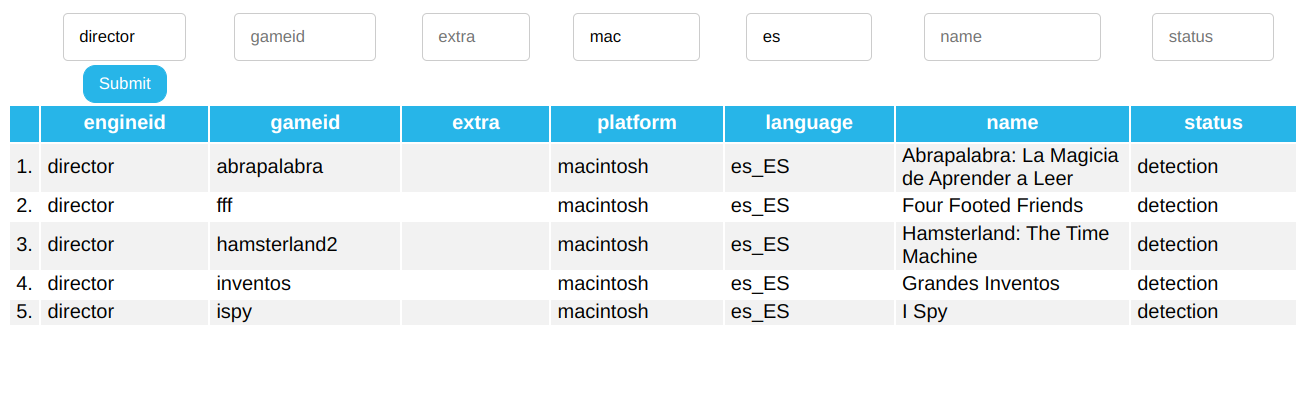
I also altered the UI for the filters in paginated tables – there’s one filter for each column now, with support for multiple filters.
That’s all for now, hope you check in next week for more progress!
Thanks for reading!