Finishing up the foundation
It’s already week 4 – and I’ve almost completed the first major part of the project! This week I finished the implementation of exporting detection entries from engines based on AdvancedDetector, and revisited the database schema and DAT parser.
This means I have now finished the code for creating DATs from game files, exporting detection entries from ScummVM and loading DATs from various sources. The only work with DATs that remains (for now) is creating logic for matching entries from untrusted sources with the detection entries.
Dealing with Detection Entries
Once I had the exporting working, I simply had to load it into the parser that I had already written. Only it wasn’t as simple as I had hoped…
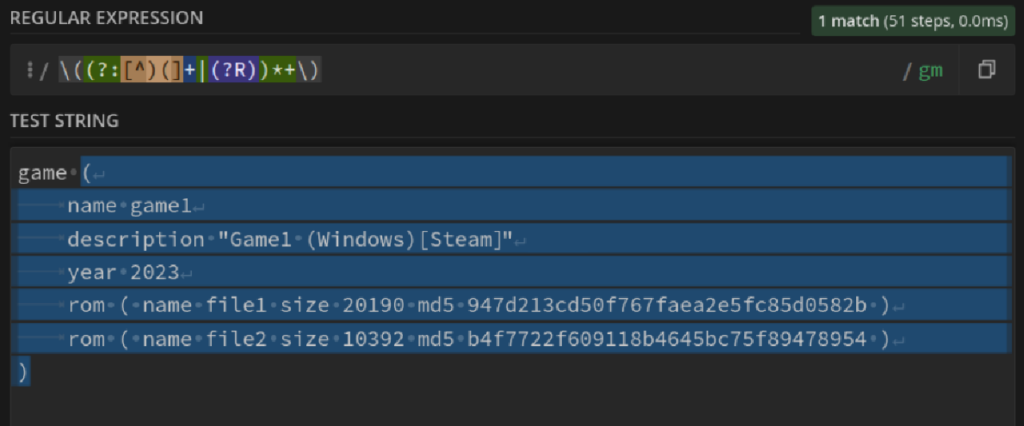
The detection entries proved to be quite an interesting foe to tackle, causing all sorts of bugs in every nook and cranny. The first snag that I encountered was filenames having spaces and brackets, which were special characters that the parser depended on. Seems my idea to use regex to keep the code clean was going to make this quite a challenge to tackle!
The solution we came up with is the enclose filenames (and other metadata like game titles) in quotes, but getting regex to ignore matches inside quotes is a little challenging, and I wasn’t going to dig myself deeper into this hole I made for myself. So I ended up rewriting the entire first part of the parser into a match_outermost_brackets() function.
We put text into quotes to get the parser to ignore their contents, but what about text with quotes themselves? The answer is using an escape character, like a backslash (\). What if the text has a backslash in it? Well, escape that too! I had to write the function to add backlashes before exporting in ScummVM, but PHP has a neat built-in function stripslashes() that gets the original string for you!
Back to the tables
Exporting and parsing the entries is one thing, but now I needed to actually put the data into the db.
After some discussion, we came to the conclusion to modify the schema a little bit to accommodate some more metadata, and also make it easier to use. After updating schema.php to fit the new design, I worked on getting the data into the right places, and added some conditionals to alter the insertion behavior depending on the source of the DAT file.
One last addition to the parser was handling different sizes and types of checksums, from full checksums to the last 5000 bytes (tail) checksums. Once I got this done, I could finally get the data into the db without a hitch.
That’s all for now. Next week I’ll be writing the matching logic and moving on the creating the website to browse these entries. Hope you check in next week for more updates!
Thanks for reading!