This week’s blog post will contain work from both week 8 and week 9, since I had college during week 8 and I wasn’t able to get much work done.
These two weeks were spent starting the final piece of the puzzle – handling user checksums, and adding some extra features to the website and CLI tool.
User Checksums
The entire point of this project is to allow users to validate their game files against those present in the db that we spent the first 2/3rds of this project creating.
The user checksums will be validated against whatever we have in the database, and there are two outcomes – the game variant in question has fully populated checksums, or it doesn’t. If it does, the process is pretty simple – just verify the integrity of the game files one-by-one, store the results in a JSON object, and send it back as a response.
If the game variant doesn’t exist in the database, we can insert the submitted checksums in the database. Since the user can submit even incorrect files for verification, we will be adding these filesets to a queue where either a moderator can approve them manually.
Framework Improvements
This week introduced a whole bunch of improvements to the website, parser and CLI scanner.
I’ve introduced a megakey column in filesets to uniquely identify non-detection filesets. This means we can skip insertion of all filesets that already exist.
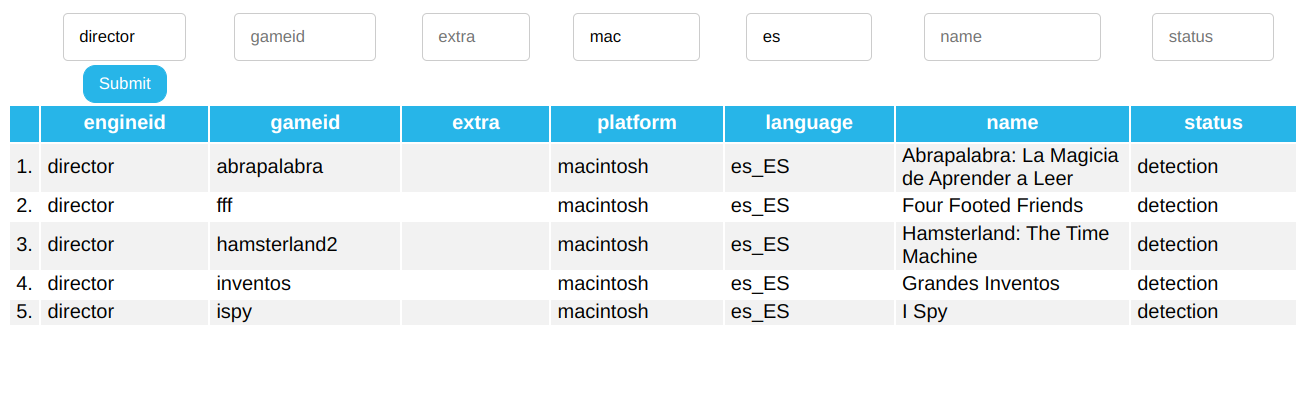
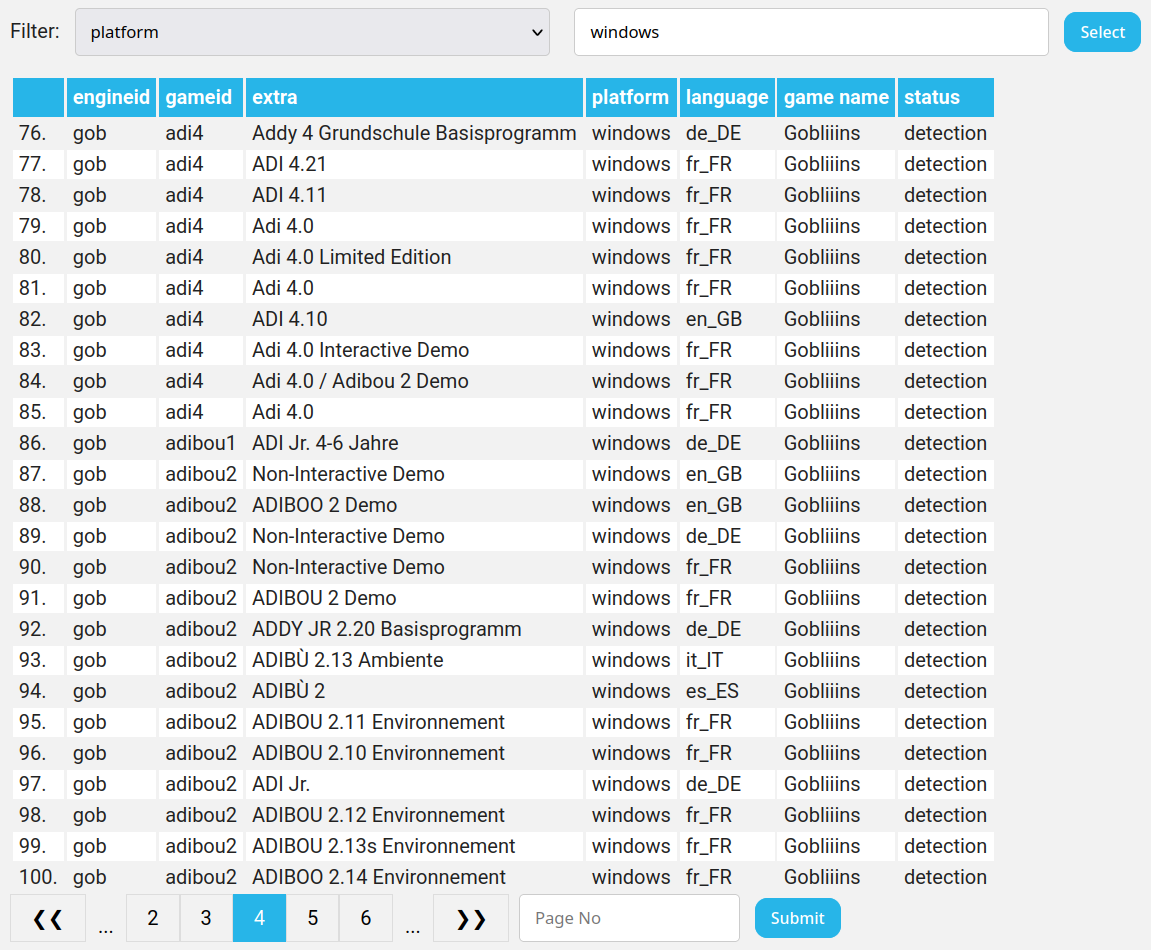
Game entries in games_list.php now have clickable rows that point to their respective fileset pages. You can also sort by any column by clicking on the heading.
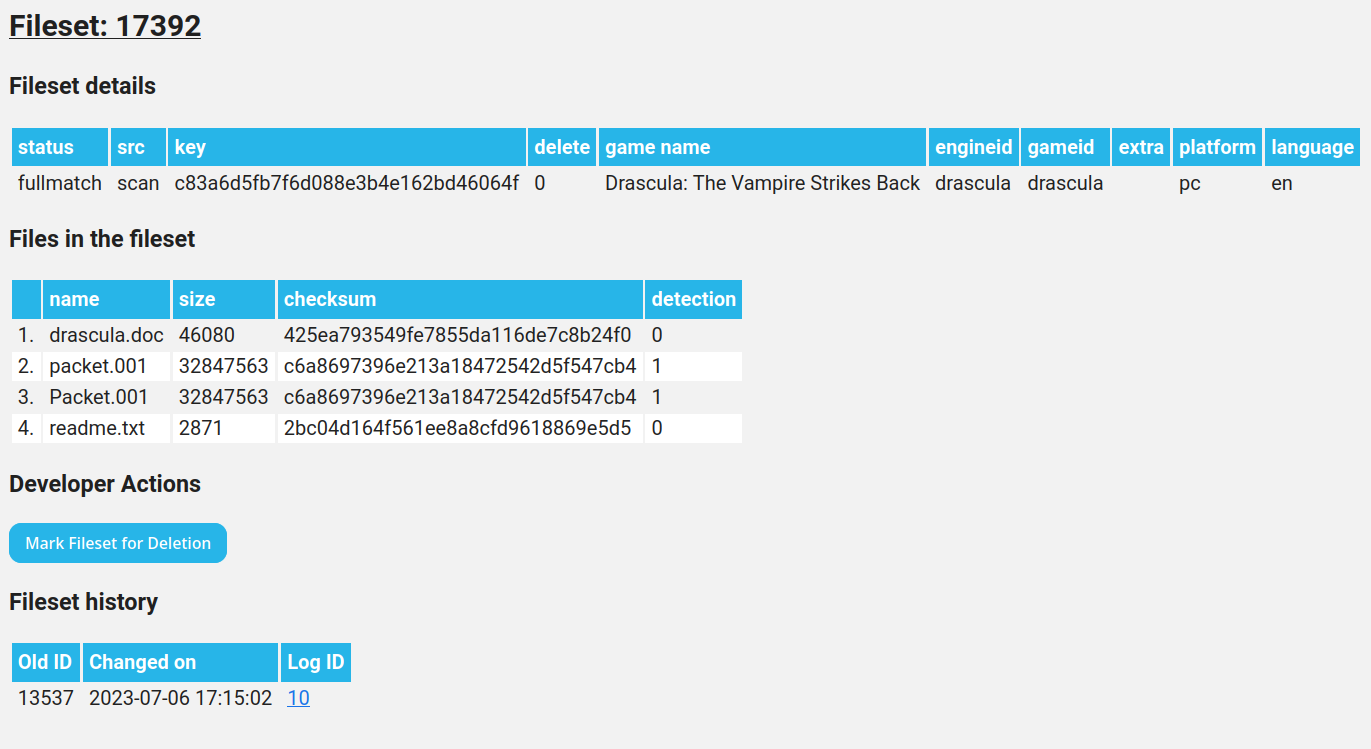
In the fileset page, you can now view checksums of all types and sizes, thanks to a new ‘Expand table’ button. I’ve also added the ability to calculate checksums of AppleDouble and .rsrc files with the scan utility.
Log entries have also gotten an overhaul, now every upload gets its own ‘Transaction’ id and every fileset inserted (or not inserted) is logged.
That’s all for now, hope you check in next week for more progress!
Thanks for reading!