- Student: eklipsed (Wyatt Radkiewicz)
- Organization: ScummVM
- Mentors: sev, criezy, lephilousophe, ccawley2011, and somean
- Project: Optimize ScummVM Rendering Code
- The 2 Pull Requests:
So originally, the goals for the project were to optimize the pixel blending code in the rendering code for the AGS game engine in ScummVM. The problem was: I completed that goal about half way through the coding period. So me and my mentors talked and what I did after was optimize the rendering code that most other engines in ScummVM use. I used SIMD cpu extensions to net a pretty huge performance gain.
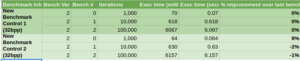
Basically, in the AGS renderer, it got a 5x improvement all around and a 14x improvement in the best scenarios. In the global rendering code for all engines to use it got a 2x improvement all around. Here are the speed up results.
The most challenging part is knowing where to start. First, you must get to know your mentors really good, eg: calls, messaging, etc. If you don’t you’ll be left alone and not knowing what to do. And second, if a coding project seems big you should take three steps.
One: Figure out where you are and the actionable steps you can take to get there. What are the big milestones you have to hit along the way? Do you need to complete something else first to efficiently implement another feature? Should you write tests first? etc.
Two: Get the bare minimum code written. I know that sounds funny, but you should just get stuff working to start. This gives you plenty of time to look at your code and to step three.
Three: Make your code the best code anyones seen. Now that you have 90% of the code written, you can optimize it and make it cleaner and tie up any loose ends like updating the tests, making a PR, etc.
Once again, I’d like to thank Google Summer of Code 2023, ScummVM for the opportunity to work on a project like this and learn so much. And I’d like to thank my mentors for helping me when I was stuck, and teaching me how to work in a team.