Hi! So far I’ve been doing pretty good with optimizations and all (you can see the current results here), and I’d like to take you through my journey in making BITMAP::draw and BITMAP::stretchedDraw faster!
Overview
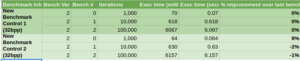
The drawing functions have a lot to deal with. They handle different source and destination pixel formats, clipping, blending, and color keying. So as you saw earlier, I took a look in a profiler to see which one was the worst culprit. Overall the worst culprit was converting the pixel formats, and then blending. Before I started on those though, I wanted to eke out some performance gains that weren’t due to that.
The Inner Loop
In the inner drawing loop (the loop that plots all the pixels row by row, column by column), it first checks to see if it’s out of bounds of the screen/bitmap, which I knew could easily be avoided if the areas were clipped off at the start so I first moved that check to the start and got about a 5% performance boost (getting rid of branches helps a lot).
Compile Time
First I wanted to move as much as I could to compile time. To do that I put the inner drawing loop into its own function and then made variations that worked on different combinations of pixel formats. Understanding what data you’re working with helps a lot when optimizing and thankfully, AGS almost exclusively uses 32 to 32 and 16 to 16 bits per pixel blits. Using that, I created versions of the inner loop for them.
Brute Force
After splitting those pixel format combinations into their own functions, I next wanted to leverage brute force to make the functions faster. Why plot a pixel at a time when you can do 4, 8, or even 16? At this step I created ARM NEON versions of the blending functions and the drawing loop, and that got me most of the performance gains, but I do have a few other things I want to point out before I end off this post.
Smaller Performance Gains
So when basically loop unrolling the drawing loop through SIMD functions, I had to do something about the left over pixels at the end of a row… The extra overhead of the normal pixel by pixel plotting at the end of a row was a big headache so I had to think up of a way to fix it. My solution was to just plot past the end of the row. Now in a normal scenario, this would obviously mess up the bitmap, but what I did was create a mask that would make source pixels that were over the end of the row the same as the destination, effectively not drawing over the end of the row. This still wouldn’t work at the last row because I would run the risk of writing past the end of the pixel buffer into unknown memory, so I still had to use the pixel by pixel method on the last few pixels in the last row of a bitmap, but overall it sped up rendering about 2 times.
What Next?
For me I know that I need to next clean up my code with comments and try adding in some micro-optimizations. Then I want to start porting my code to x86 processors. At that point, I will have completed what I set off to do, but I plan on trying to port this blitting code to the general ScummVM blitting routines.