Last week I pretty quickly finished the merge, there was only a bit of refactoring left. After that I worked on a tool that could recreate Mission Supernova datafiles containing images, which would allow us to translate them.
The MS datafile format is pretty simple and it reminds me of .bmp images (there is a header, after that palette and after that pixel data). At the first 4 bytes is size of the pixel data field. After that is 1 byte, which is the size of the palette. The palette follows after that. Pretty interesting thing is, that each color is brightened by the engine (shifted by 2 to the left), so we have to count with that when making a new image and generating palettes for them. This also means, that we loose a lot of colors (We for example aren’t able to encode the whole 256 colors of grayscale). After the palette is information about sections. Section is a image, that can get rendered on top of other sections (images). The information is basically only it’s size, location on the screen and location of it’s pixel data inside the file. Next is click field information. Click field is similar to section, it has size and location on the screen, but it doesn’t have image assigned to it. After this follows 2 to 258 bytes used to decompress the image. The last thing is the pixel data for all the sections.
The tool right now is semi-automated (I think automated enough). As it’s input it uses files containing palette, section and click field descriptions and a .bmp file for each section. It just copies the descriptions into the file after which it takes the pixel data from each .bmp image and copies them too. The thing, that isn’t automated is, that user has to tell the tool by a command line argument, where the pixel data of the images start (how many bytes of each .bmp image to skip)
I wrote the reasons, the tool is needed in the last post, but just to remind you. The main reason is, that we need to translate this image:

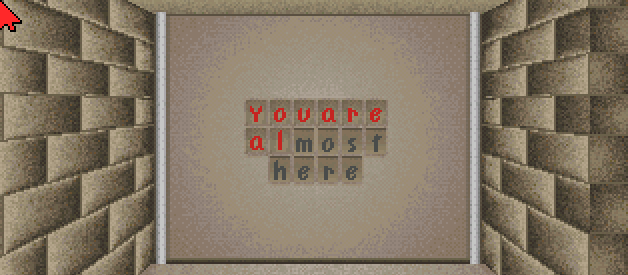
This writing basically means “You are almost there” and player is supposed to push certain letters using a clue on a note to open the door. A temporary solution was to translate the note to English (translating the password too), changing the password on the door and adding subtitle saying “You are almost there” when entering the room with this door.
When translating the image, I had quite a few problems with palette:

But after that I noticed, that the first 16 colors don’t change and the image palette starts on 17th color of the engines palette, so I shifted the palette by 16 colors (just adding blue to the front a few times, which isn’t used in this image) and I got this:
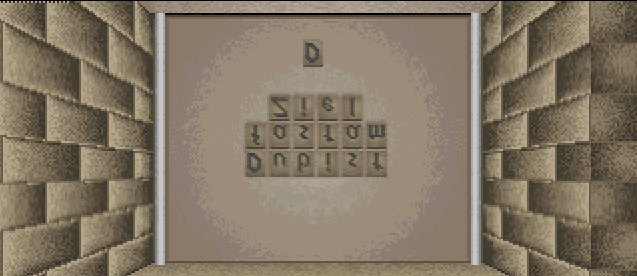
You probably noticed, that the picture is upside down and that there is a noticeable lighter circle around the writing. But with the help of dithering and mirroring the image in gimp I managed to translate the whole image:
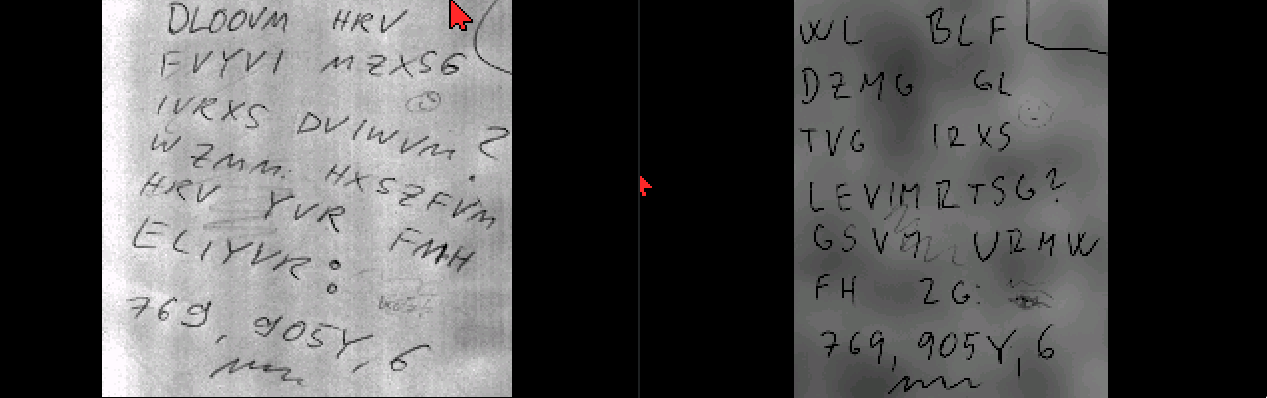
And thanks to having the tool, I was able to add a better version of the translated ciphered image too:
Now I will fix some more bugs, me and my brother found while playing the game, then I will add an “improved” mode making some repetitive and annoying tasks less repetitive and less annoying.