First of all, I finally passed my exams! I’ve got a few things to do, but in July I’d be completely free to work on my project. That’s why I wasn’t too active this week and wouldn’t be on the next one.
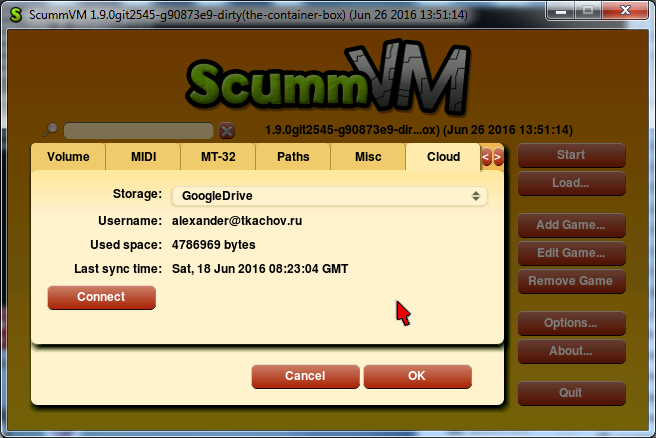
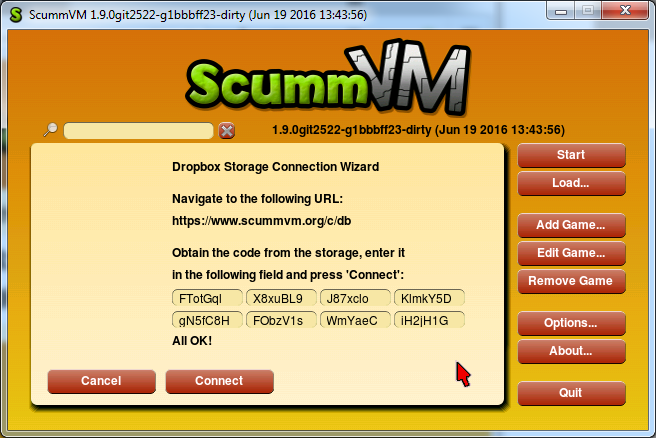
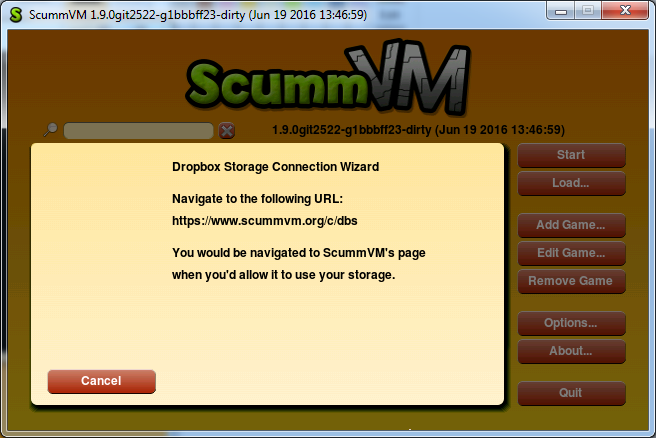
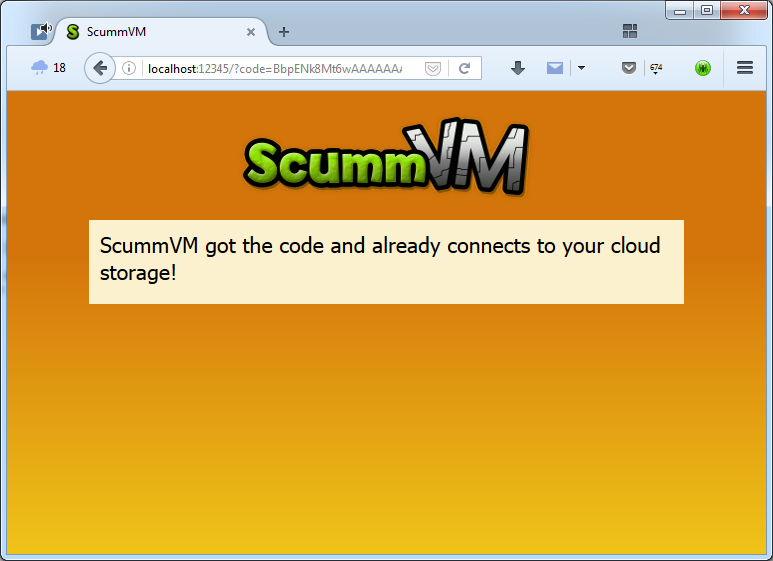
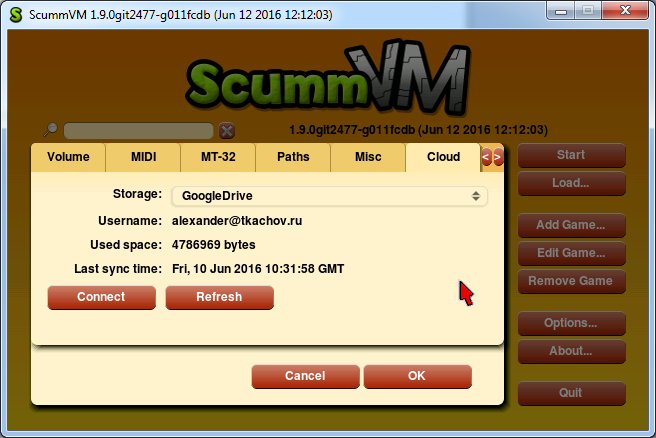
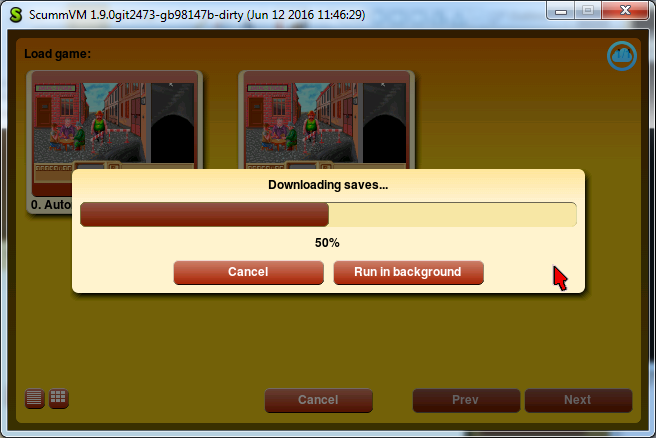
So, this week I was working on non-cloud-related thingie: a new GUI widget, which would contain other widgets of unlimited total height — the Container. Well, it’s actually a ScrollContainerWidget, and the main thing it has is a scrollbar. As I said in the previous post, one of my dialogs — the storage wizard — is too lengthy to be displayed in that area where ScummVM shows its dialogs. We decided that I should implement the Container, so we can put dialog contents in it, and in these cases when there is no room to display all of them, the scrollbar would automatically appear and no overlap will happen.
The first thing I changed was label — it already has a clipping rectangle, so I only had to pass the right values. Then the fun (to be read as difficult) part started. Widgets doesn’t have any clipping rectangle, which means you can’t just make the button draw only part of it. And, well, each widget has its own method, so it means I’ve got to change all of these in order to make them support clipping.
I started with buttons and PopUpWidget, because those are used in the Cloud tab of the Options dialog. Their drawWidget() method calls the corresponding drawButton()/drawPopUpWidget() method of ThemeEngine. ThemeEngine uses queueDD() and queueDDText(). Some DrawData objects are created in there, then their draw steps are called. If I recall correctly, draw steps are methods of VectorRenderer, which has VectorRendererSpec backends with implementations of these. So, I’ve got to pass that clipping area information from Widget though ThemeEngine and DrawData objects right to VectorRendererSpec and use it there.
Each of those draw step implementations has some additional functions in VectorRendererSpec. And these functions have some complicated logic and lots of macros usage. And none of these happen to think that clipping would ever be needed.
So, buttons are using drawRoundedSquare() draw step method. To minimize the possibitility of breaking something, I decided to leave these methods and add new ones — drawRoundedSquareClip() in this case. It checks that clipping is actually needed (i.e. button area is not completely in the clipping area), and if not, uses the original one. If clipping is needed, then other Clip-versions are used. So, drawRoundedSquareAlgClip(), drawBorderRoundedSquareAlgClip(), drawInteriorRoundedSquareAlgClip(), gradientFillClip(), blendFillClip(), colorFillClip() and a lot of macros with names like BE_DRAWCIRCLE_XCOLOR_BOTTOM_CLIP() arrived.
All this — for rounded squares. And there are also triangles, circles and other draw steps, which I didn’t touch yet. But still, Container already works with buttons, PopUpWidget and labels, and I guess in some cases it would be enough to add new draw<WidgetName>() and use all these methods, which already do clipping, so it should be getting easier as I go further. The plan is to make all other widgets support clipping, so Container could be used with any of them. Apart from that — it seems to work fine.