
According to my proposal’s schedule, I should’ve been working on Storage interface, token saving and Dropbox and OneDrive stubs this week. I’ve tried to schedule less work before the midterm because I’ve got some exams to pass. Still, I managed to do most of that first week plan with my preparation work. So, I’ve finished that by Tuesday and started working on the things planned for the second week: files downloading.
I’ve also implemented DownloadRequest class that Tuesday. It just reads bytes from NetworkReadStream and writes them into DumpFile.
There was some small problem with DumpFile: it fopen’s a file (creating it, if it doesn’t exist), but it assumes that the file is located in some existing directory. When you’re downloading a file from the cloud into your local folder, you might not have the same directory hierarchy there. Thus, fopen fails and no download occurs. As there was no createDirectory() method in ScummVM, I had to implement one. So, now DumpFile accepts a bool parameter, which indicates whether all directories should be created before fopen’ing the file.
Then we’ve decided I should «upgrade» our Requests/ConnectionManager system by adding RequestInfo struct and giving each Request an id. User could use an id to locate the Request through ConnMan and ask it to change its state. That’s mostly needed when we want to make the same request again: for example, if some error occurred, we probably would like to try again in a few seconds. This system added RETRY state for Requests, so user’s code can easily ask to retry Request. The original idea with RequestInfo and ids was rethought, so now we’re actually using pointers to Request instances. That way one can easily affect Request: cancel, pause or restart it with its methods.
With that system I could easily implement the OneDriveTokenRefresher. That might be not the best class name, but it describes it quite well =) OneDrive access tokens expire after an hour, so that’s very sad to get an error because you’re working with the app more than an hour. This class wraps the usual CurlJsonRequest (which is used to receive JSON representation of server’s response) to hide errors regarding expired token. Basically, it just peeks into received JSON and, if there is an error message, refreshes the token and then tries to do the original request again, using the new token. With that new system, it just pauses the original request and then retries it — no need to save the original request’s parameters somewhere because they are just stored along with the paused request.
After I finished that useful token refreshing class, I’ve implemented OneDriveStorage::download(), thus completing the second week plan too. The plan also has «auto detection» feature, which is being delayed a little because it would be called from the GUI and I’m not working on the GUI yet. Yet, there was no folder downloading in my plan, and it’s obviously a must have feature, so that’s what I did next. The FolderDownloadRequest uses Storage’s listDirectory() and download() methods, so it’s easy to implement and it works with all Storage implementations which have these methods working.
I actually implemented OneDriveStorage’s listDirectory() a little bit later because there is no way to list directories recursively in OneDrive’s API. There is such opportunity in Dropbox, so it takes me one API call to list whole directory and all its subdirectories contents. To list OneDrive directories recursively, I had to write a special OneDriveListDirectoryRequest class, which lists the directory with one API call, then lists each of its subdirectories with other calls, then their subdirectories, and so on until it lists it all.
I’ve been asked to draw some sequence diagrams explaining all these Requests/ConnectionManager systems, so that’s what I’m going to do now. I’m not a fan of sequence diagrams and I’m going to draw them in my own style, which, I believe, makes them simpler.
UPD: here they come, two small diagrams (available on ScummVM wiki too):
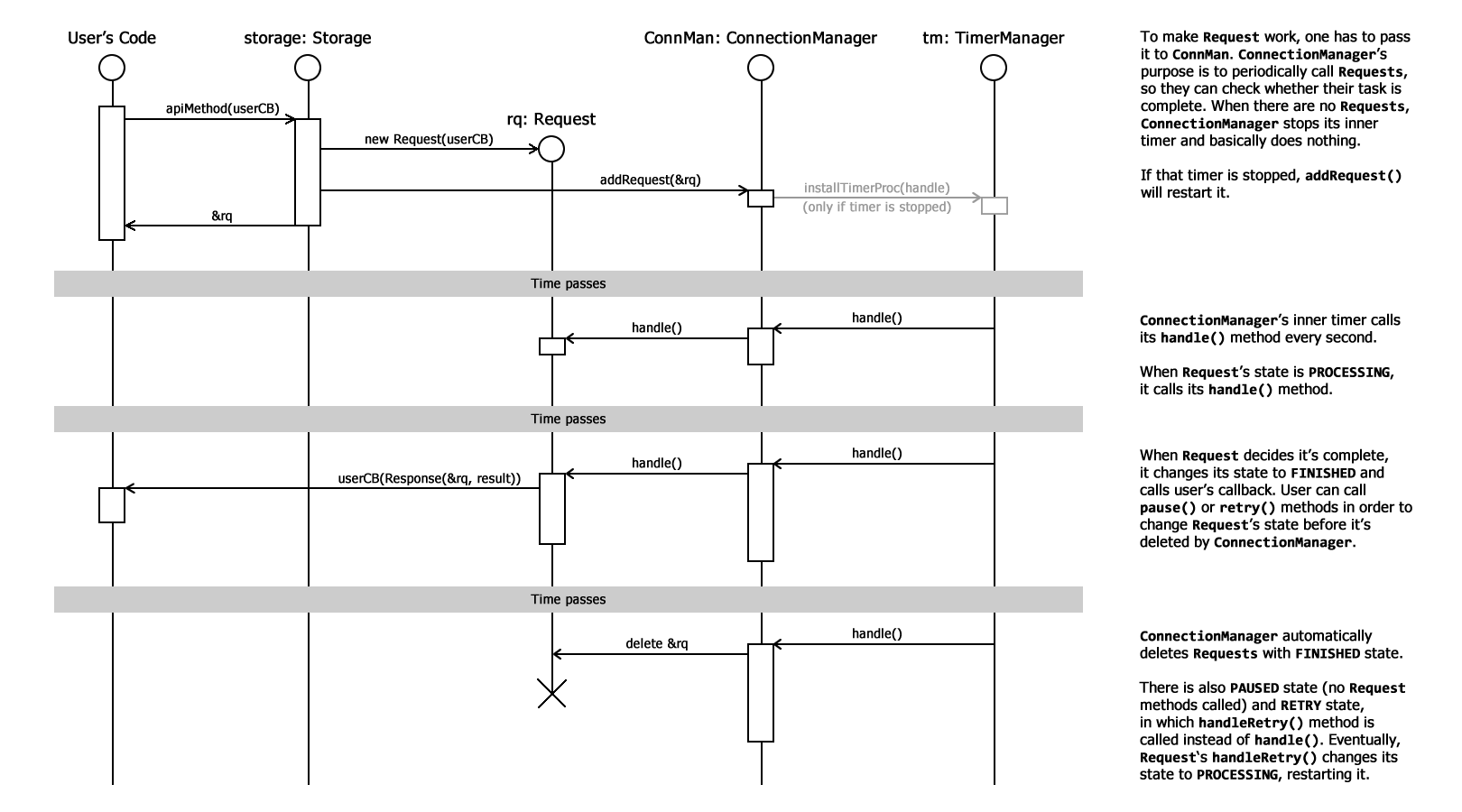
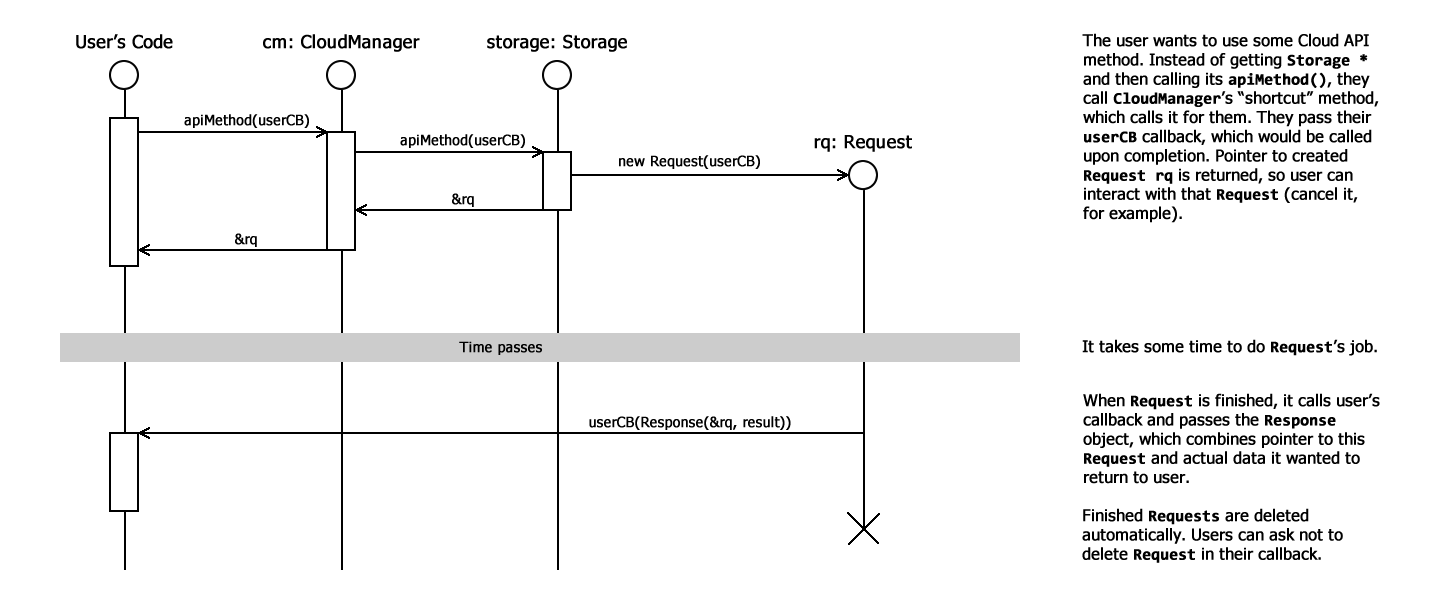
File sync comes next week and I guess I’m going to discuss that feature a lot before I actually start implementing it.