Goals of the Project
The aim of the project was to integrate a File Integrity Service into ScummVM, along with a supporting application for managing the database. The main goals were:
- Populating the database with the detection entries used by ScummVM for game detection, followed by existing game file collections containing full MD5 checksums.
- Developing a utility for scanning game directories and generating data to further populate the database.
- Allowing users to verify their game files through this integrity service, and contribute new game variants.
- Building an application for managing the server and the database with role based access.
What I Did
- A large portion of the work involved rewriting the codebase, as the existing logic for filtering and matching the filesets was not correct.
- For ensuring correctness of code while matching old game collections, a lot of manual checking was required for over 100 different engines.
- For the scan utility, I extended support for legacy Mac file formats (AppleDouble, MacBinary, etc.), ensuring proper matching with filesets present in the database.
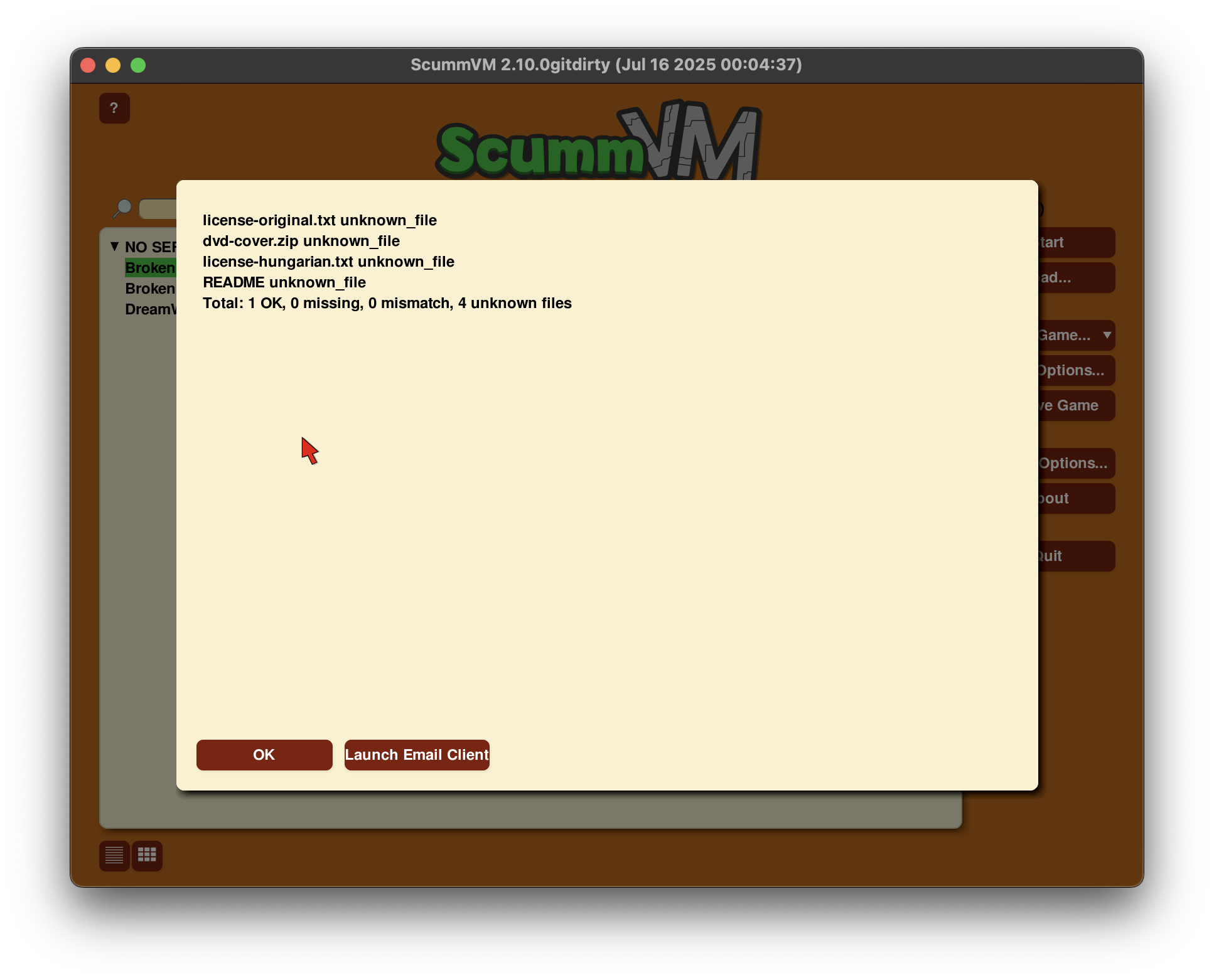
- For user integrity service, I worked on reporting information like Missing files, Unknown Files, Mismatched Files and Ok files. Further, I built a moderation queue system for user submitted files and also solidified the checks on user submitted data to allow submission of only valid data.
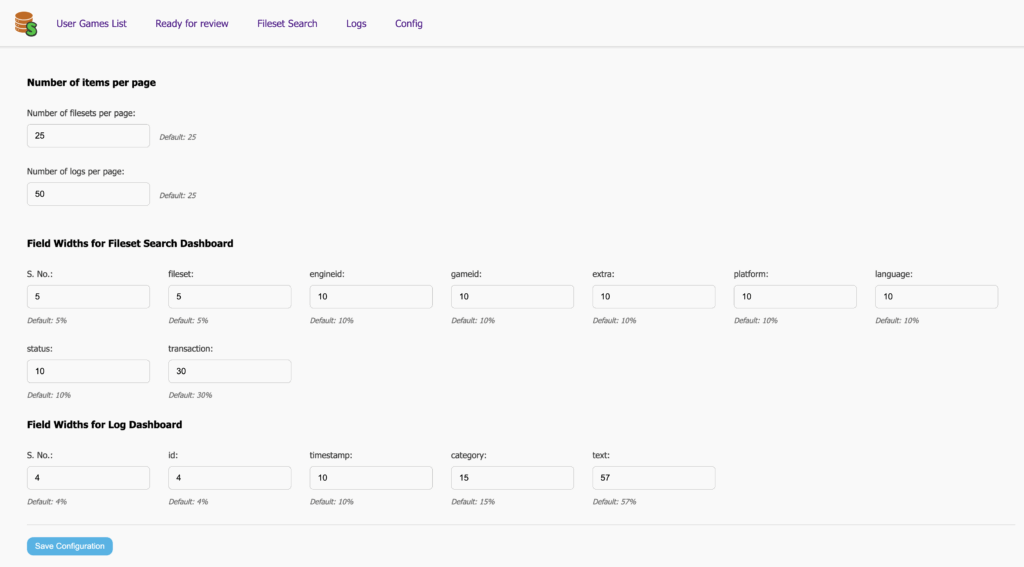
- For the application, I added support for manually merging filesets, updating filesets within the application, improved search filtering and logging. Further, I added a configuration page for customising some user display settings and integrated Github OAuth with role-based access control (Admins, Moderators, and Read-only users).
Current State and What’s Left
The application is in a complete working state. All the workflows are functioning properly. The remaining step is to populate the database with all existing data so the integrity service can start operating officially.
Code that got merged
List of PRs that got merged –
Server Side:
User File Integrity Check, Web App updates and Project Restructuring
Scan Utility and Scanned fileset matching
Macfiles support, Initial Seeding and matching with old game collections
ScummVM:
Freeze issue for Integrity Dialog
Challenges and Learnings
The most challenging part was handling the variations across engines and game variants, and ensuring correctness in the filtering and matching process while populating the database. This often required manual validation of filesets. Working on this project taught me about the level of care needed to maintain the code and the importance of sharing the thoughts with the team. It was a highly rewarding experience working with ScummVM, and I am very grateful to my mentors Sev and Rvanlaar for their guidance and support throughout the project.