Last 2 weeks I’ve worked on developing of format for holding recorded gameplay data. Why this needed and how does it work you may read under the cut.
In first versions I wrote without formatting and then just read it in same order to the written. It worked, but wasn’t flexible and hadn’t any abilities to provide backward compatiblity in future. And there was a problem with navigation between file sections: for example, file has a header section, a section with info about autor and a section with gameplay data.
So, it was necessary to find the way to structure the data. I thought that the most appropriate format for current purposes is the RIFF, i.e. use containers with fields of unique identifier and size for every file section. It give us opportunity to find identify any section in file. Also we can easily skip any unsupported section.
Now file has following sections:
PBCK //format id, length = file length - 8
VERS //version of recorder
HEAD //Header, contains unnecessary info about author
HAUT //Author's name
HCMT //Comments
HASH //table of MD5 hash of game files
HRCD //record for one file
HNAM //name
HMD5 //MD5 hash
RNDM //Seeds for random number generator
SETT //Game's settings
SKEY //Name of setting
SVAL //Value of setting
RCDS //Gameplay data
RCDS section always has 0 in size field, because isn't possible to calculate it during the recording.
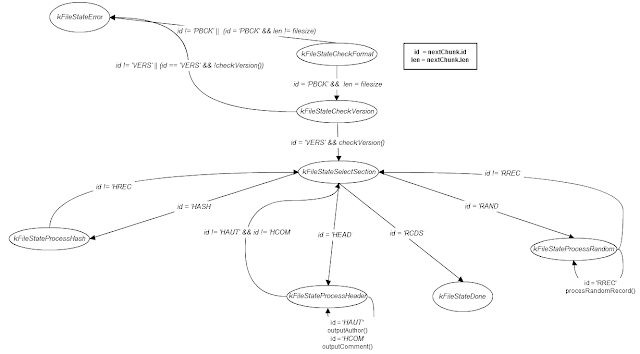
To process this file, I wrote state machine which may be illustrated by following diagramm: