This week’s work went relatively smoothly, and I encountered nothing too challenging. At the beginning of the week, sev reminded me that my original regex was matching too slowly. I reviewed the code and realized I had fallen into an X-Y problem myself.
That is, I was focused on using regex to solve the string-matching problem, but I overlooked the fact that using an extra regex might not be necessary at all. My current expression can indeed match all the cases in the existing dat files, but the problem is that it’s not necessary to do so. Since the structure within each “rom” section is fixed and different blocks are always separated by a space, token matching is sufficient. There’s no need to use a complex regex to cover all edge cases, and the performance will be much better (linear time complexity).
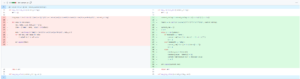
As planned last week, I added a detection_type column to the file table. This makes it clearer when recalculating the megakey.
Due to the addition of the detection_type column and set.dat , the code logic requires some extra handling. Therefore, I also refactored the original code, decoupling the matching-related code through modularization to facilitate future development and expansion.