In the past few weeks, I completed most of the work on the detection part, including merging and deduplication. This week, I mainly focused on merging the remaining types of dat files.
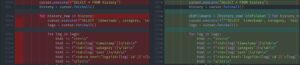
After discussing with sev, I realized that my previous idea of merging was too simple.
Using a state diagram, it looks like this:
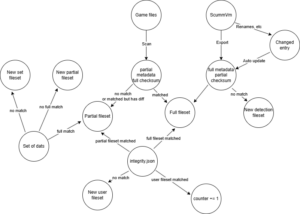
After clarifying my thoughts with this diagram, the subsequent work became much clearer.
First, I found that the original regex matching rules only applied to detection-type dat files and did not adapt well to scan-type files (mainly because the md5 types would fail to match). Therefore, I made some attempts and modified the regex from r'(\w+)\s+"([^"]*)"\s+size\s+(\d+)\s+md5-5000\s+([a-f0-9]+)' to r'(\w+)\s+"([^"]*)"\s+size\s+(\d+)((?:\s+md5(?:-\w+)?(?:-\w+)?\s+[a-f0-9]+)*)'.
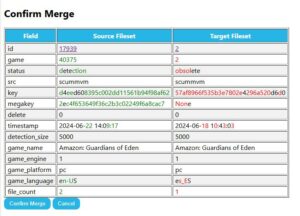
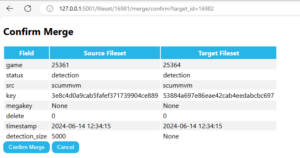
At the same time, I refactored my previous code for detecting duplicate files in detection and merging them. The original code did not query and match each entry from the checksum table during the merge, but this step is necessary to minimize collisions.
Initially, I wanted to reuse the code for viewing extended checksum tables within the fileset, but later I found that such reuse introduced bugs and made maintenance difficult. I was simply complicating things.
The logic is quite simple: for each file, compare its corresponding checktype checksum. If they match, it can be considered the same file. When merging scan into detection, this operation removes the original file from the fileset while inserting the file from scan into the fileset (since the information is more complete), but retains the detection status.
Speaking of detection status, a better practice would be to convert it from a Boolean type to a string type (indicating which md5 type it is). This would make recalculating the megakey more convenient. However, I haven’t had the opportunity to modify it this week due to the extensive logic involved. I’m considering adding a new column to the database instead of modifying the existing type. I plan to implement this idea in my work next week.