This week’s work mainly focused on wrapping things up as the end of the project is approaching, and I am striving to refine the details.
Quantitatively, I accomplished the following tasks:
- I thoroughly tested my code following the correct workflow.
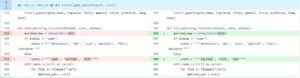
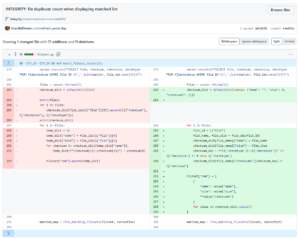
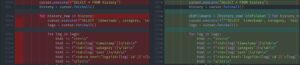
- In the old version, when matching filesets in the command line, it would repeatedly create the same fileset multiple times (manifested in the logs as multiple occurrences of “Updated fileset: xxxx”). After some debugging, I found the problem.
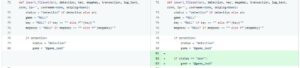
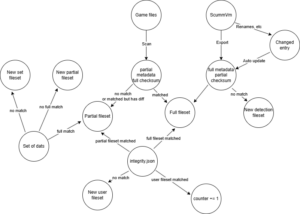
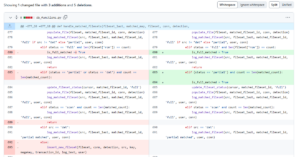 As shown in the diagram, the old version would automatically insert a new fileset after all possible match failures, which seems reasonable. However, I had already implemented the logic of “creating a fileset first before matching” in a previous version. This led to duplicate logs since the outer loop of this code was
As shown in the diagram, the old version would automatically insert a new fileset after all possible match failures, which seems reasonable. However, I had already implemented the logic of “creating a fileset first before matching” in a previous version. This led to duplicate logs since the outer loop of this code was
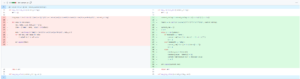
for matched_fileset_id, matched_count in matched_list:,
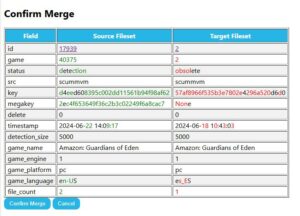
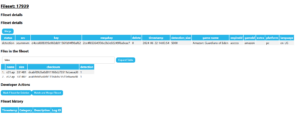
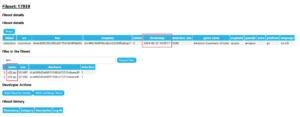
meaning that the number of potentially matched filesets would result in the same number of duplicate logs. This issue was minor but stemmed from my lack of careful consideration. - I added several new features: for instance, I added checkboxes next to each file on the fileset detail page for developers to conveniently delete unnecessary files, included sorting functionality in the fileset table on the fileset page, and highlighted checksums corresponding to detection types. These features did not involve complex logic, as they were primarily frontend enhancements, and therefore were completed without difficulty.
Looking back at my entire project, I have finished nearly 3000 lines of code over 12 weeks.
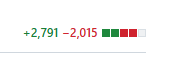
I am pleased that most of what I’ve accomplished so far has met expectations. However, there are still some improvements needed before deployment, such as adaptation for MacBinary and other Mac formats, and user IP identification. My sense of responsibility drives me to continue refining this project even after GSOC ends until it can be truly put into production. I look forward to that day! 😄