I’ve just finished adding short-circuit detection to the decompiler. This detection is done as part of the initial group creation.
The algorithm for detecting short-circuiting is as follows: Two groups, A and B, that follow sequentially in the byte code (no instructions appear between the last instruction of A and the first instruction of B), are merged if:
- Both group A and B end with a conditional jump (they have two possible successors each)
- For each outgoing edge from A, the edge must either go to B, or to a successor of B – in other words, merging may not add any new successors. More formally, succ(A) ⊆ {B} ∪ succ(B), where succ(X) is the possible successors for X.
To make sure the merging happens correctly when several groups should be merged, the groups are iterated in reverse order (the group with the last instruction is processed first).
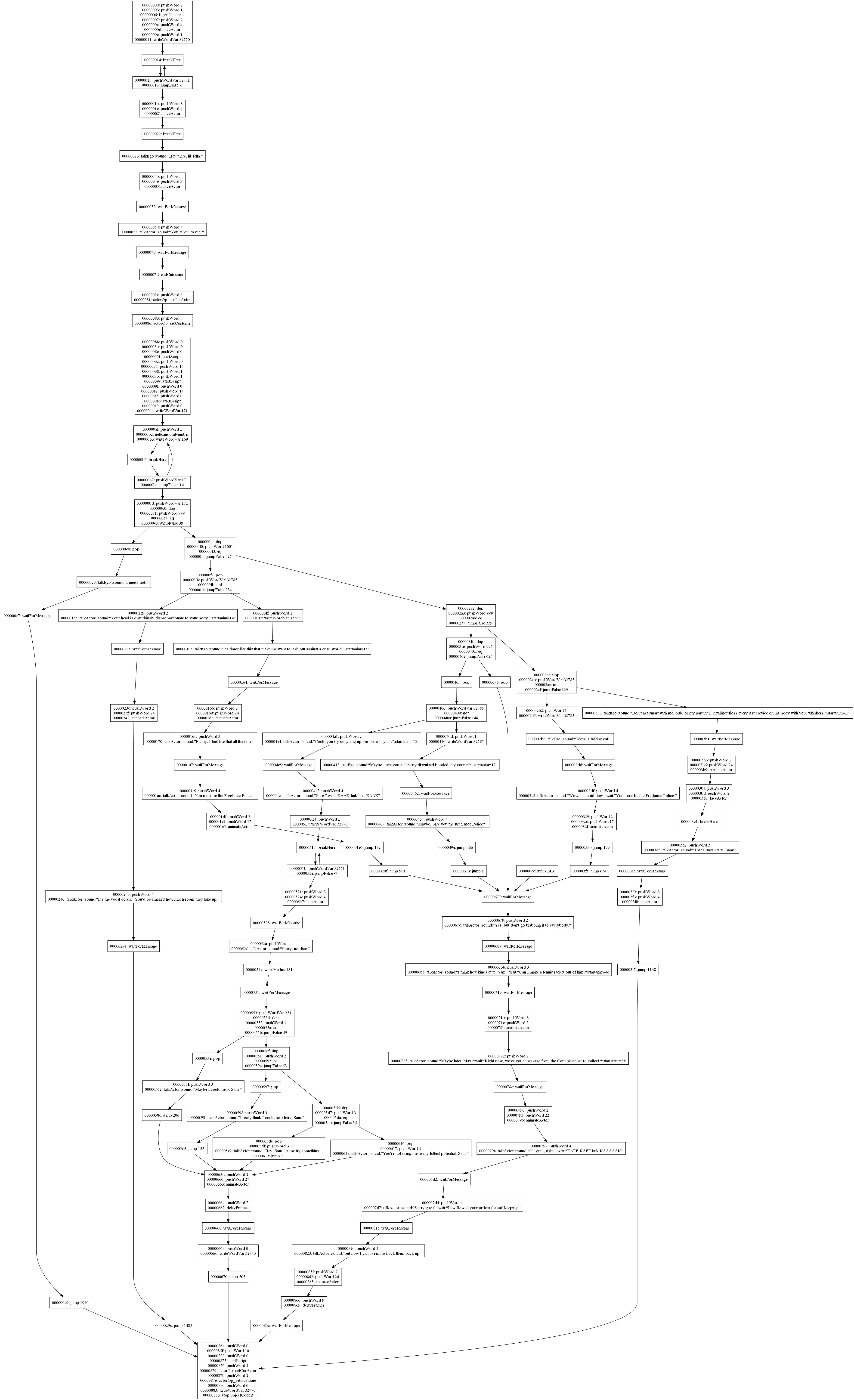
Here’s an example to show how this works. The number in parenthesis is the effect that instruction has on the stack, and for ease of reading, the jump addresses have been made absolute.
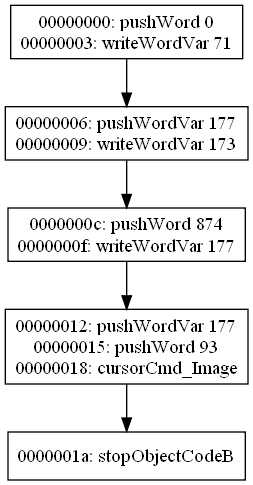
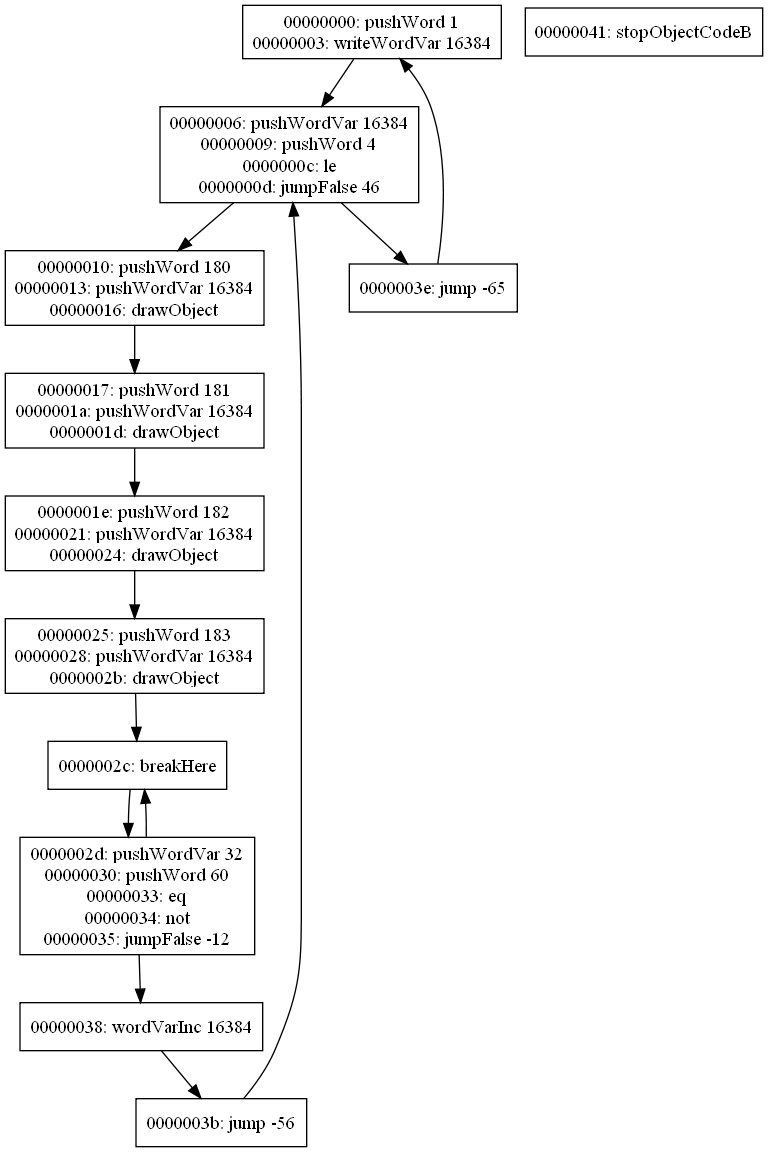
0x00: wordVarDec 123 (0) 0x03: pushWord 41 (1) 0x06: pushWordVar 321 (1) 0x09: eq (-1) 0x0a: jumpTrue 0x17 (-1) 0x0d: pushWord 42 (1) 0x10: pushWordVar 123 (1) 0x13: eq (-1) 0x14: jumpTrue 0x00 (-1) 0x17: stopObjectCodeA (0)
Normally, there would be 4 groups in this script: the first and last instructions would be groups on their own, and instructions 0x03 through 0x0a would be a group, as would 0x0d through 0x14. For simplicitly, we’ll number these groups 1 through 4.
0x00: wordVarDec 123 (0) === 0x03: pushWord 41 (1) 0x06: pushWordVar 321 (1) 0x09: eq (-1) 0x0a: jumpTrue 0x17 (-1) === 0x0d: pushWord 42 (1) 0x10: pushWordVar 123 (1) 0x13: eq (-1) 0x14: jumpTrue 0x00 (-1) === 0x17: stopObjectCodeA (0)
The possible successors for group 3 are group 4 and group 1, while the possible suceessors for group 2 are group 3 and group 4. Since group 4 is a shared successor, and the group 2-group 3 link becomes irrelevant due to the merge, the two groups can be merged to a single one since the algorithm detects them as a short-circuited condition check.